毎日の小さなアウトプット
毎日こつこつアウトプットする習慣を作りたいと思っていたのですが、
という記事を見かけて、私もTIL(Today I Learned) をやってみようと思ったので TILについて&どのようにやっていくかを考えてみました。
WHY
- 何かを毎日アウトプットする習慣をつけたい。
- 毎日の気になったこと、覚えたこと、新しく気付いたこと、学んだことをどんな形でもいいからアウトプットしたかった。
TILとは
Today I Learnedの略。 Github上にTILというリポジトリを作成してそこに今日覚えたことを書いていく。 (githubで検索するとtilというリポジトリがけっこう見つかる)
塵も積もれば山となるみたいな感じ。
ref. https://qiita.com/sitmk/items/239335b4ed0c3c797add ref. https://syossan.hateblo.jp/entry/2016/02/16/144305
実際のリポジトリ
https://github.com/jbranchaud/til
カテゴリごとにディレクトリを作成し、勉強した内容などをmdファイルでまとめている。


HOW
https://aloerina01.github.io/blog/2019-03-22-1
↑を参考に
- 何か読んだり考えたりしたらそのログをIssueに残す
- ブログに書くほどじゃないネタを雑にIssueにまとめる
- ちょっとした実装を日付毎のディレクトリにCommitする
という感じでやっていく。
毎日アウトプットする習慣を作ることが目的なのでブログに書いてある通りかなりハードルを低くして、やっていく。
5月中旬からはじめて、毎日続いているわけではないのですが...
毎日コツコツ小さなアウトプットをしたいと思っているのでこのブログで意思表明です。。。
ソフトウェアテスト技法ドリルを読みました
最近、担当している機能のリリースしたのですが、リリース後のバグが多く…
テスト設計やテストケースの洗い出しがきちんとできていなかったと実感しました。
会社のテストエンジニアに相談したらソフトウェアテスト技法ドリルをおすすめしてくれたので読んでみました。
個人的に重要だと思ったところ&知らなかったことをまとめてます。
どんな本
- テスト技法の正しい使い方が実践的に学べる
- テスト技術者向けに、テスト設計および実施のノウハウを披露し、解説している本。
- 誰が読んでも理解ができ、すぐに実践できることを目標にソフトウェアテスト技法を一連の流れで説明
- 一連の流れとは、テストの視点・観点といった「点に注意を向ける」といった話から、テストの目的の一つである品質に関する情報を提供する「多次元の品質」まで
目的
テスト技法の正しい使い方や一連の流れを学ぶことで、実践的にテスト設計できるようになる。
1章 点に注意を向ける
怪しい点に向けるテストについての章
- 仕様書を読むときは3色ボールペンを使うことをおすすめしてた
- 仕様書で曖昧なところは具体的なデータを示し、そのデータを見て、「間」「対称」「類推」「外側」を考える癖をつける
- 思っきり意地悪になってテストデータやテスト手順をつくる
- 過去の経験を活かすこと
テストの大部分は、仕様書を読んで怪しいところを見つけて確認する
テストの大部分を占める怪しいところをテストする方法の章
2章 線を意識する
連続して変化する数値や文字コードについてテストする方法について
同値分割と境界値分析
同値分割 入力される可能性があるデータをすべてテストするのはたいへんなので入力をグルーピングしてそれぞれのグループから代表となる値を選びそれだけをテスト 同値分割した各々のグループのことを「同値クラス」と呼ぶ
境界値分析 代表となる値を選ぶときにそれぞれのグループの端っこを狙う 境界値に関係するバグは数が多い
- 境界値、端っこにはバグが隠れている可能性が多い。(図に描いて問題を正しく理解するように)
- 異常値は他の異常値を隠す
- 線を意識することで、端っこ以外の点をテストから除外し効率化することができる
3章 面で逃さない
- 1〜2章は主にデータに焦点を当ててテストを減らす方法について
- ソフトウェア自体はデータからなるのではなく、ロジック(論理)の塊から構成されている。
- ロジックとは入力の組み合わせによる特別な動作。ソフトウェアの入力が系統的にロジックを網羅し、正しく動作することをテストするテクニックを身につける必要がある。
ドメイン分析テスト
関係性がある複数の変数を同時にテストする方法
on/off/in/out
on : 着目している境界値のこと
off : onポイントに対して境界値分析をしたときに見つかる隣接したもう一つの境界値のこと
in : ドメインの内側の値
out : 外側の値
多くの変数があった場合は、着目する一つの変数についてon offを変化させ、他の変数についてはすべてinにしておけばその変数のon/offポイントを確実に評価することができる。 Binderのドメイン分析テストマトリクス
方法
- まず変数を探す
- それぞれのon/off/in/outについて考える
- ドメイン分析テストマトリクスを作成する
ドメイン分析テストは、関連性がある(特に数式で結ばれている)複数の変数をテストするときに基本となるテクニック(範囲を扱うとき等)
3.2 デシジョンテーブル
デシジョンテーブルで扱う変数は倫理式で結ばれている
- AND
- OR
- NOT
if文やswitch文はすべてデシジョンテーブルにできる
3.3 原因結果グラフ
条件が多くなると大きなデシジョンテーブルを作成する必要がある。
プールグラフから単純な規則を使ってデシジョンテーブルを作成する ソフトウェアのテストで利用するブールグラフのことを原因結果グラフという
3.4 CFD法
CFD(Cause Flow Diagram)法
複雑な論理関係の仕様から重要なテスト条件を漏らさない技法 「原因の集合」と「原因どうしのつながり」に着目し、流れ線でつなぐことによって仕様を図式化し、そこからデシジョンテーブルを作成する技法
原因を集合で表現することで明示的に補集合についてテストの視点が届く
まとめ
- ドメイン分析
- on/off/in/out
- デシジョンテーブル
- 論理的な関係をテストする基本となる表
- 同じロジックをまとめるテクニック(デシジョンテーブルを圧縮)
- 原因結果グラフ
- 論理関係を目で見える形で表現したもの
- CEGTestで具体的な事例を解いてみる
- CFD法
- 原因結果グラフの欠点である難しさを改善したテスト技法
- ロジックを設計するときに使用すれば、ロジックの問題点が見つかる
- 図式化されているのでレビューがしやすい
4章 立体で捉える
- 新規機能追加機能によってこれまで表にでてこなかった母体のバグが魔物のように目を覚まし、バグとなって顕在化することがある
- 関連性を効率的にテストしていく必要がある。
- ソフトウェア自体は3章と同様に2次元で考えて、そこに組み合わせるべき「要因を選ぶ目線」を追加し立体で考える。
- 要因を選ぶ目線
- ソフトウェアの利用者である顧客の視点(6W2H)
4.1 HAYST法
仕様上は機能と機能の間には関連がないことが前提になっいるテスト(直交している) 直交している機能を組み合わせたときに、本当に問題が起こらないことを効率よく確認する方法
4.1.1 HAYST法を使う意義
一般にソフトウェアは各機能に対して、それぞれを独立してつくろうと努力し開発されるもの。 実際はどこかで意図しない関連性が生まれてしまう。
そこでHAYST法を用いてテストをすることが重要になる
4.1.2 因子と水準の抽出
怪しい因子を見つけて、それをHAYST法、またはペアワイズで表に組み上げてテストすることが重要
- 因子: テスト対象の項目(判定または条件)
- 水準: 因子の取り得る値
- 強さ: 因子の組み合わせ数
どうすれば、有効な因子と水準が見つかる?
6W2Hで考える - When - Where - Who - What - Why - Whom(誰のために) - How - How much(価格、量)
4.1.3 FV表
組み合わせるべき因子水準が見つかり、テスト対象の理解が進んだところで FV表を作成
| No. | 目的機能(Fr) | 検証内容(V) | テスト技法(T) |
|---|---|---|---|
4.2 ペアワイズ
4.2.1 ペアワイズテストとは?
ソフトウェアのバグの多くが1つまたは2つの因子の組み合わせによって発生している という事実に基づいてテストケースを作成する方法。
すべての因子の組み合わせでなく、 2組の因子(強さ2) における水準の組み合わせをすべて網羅することによってテストケースを制限したもの
因子:テスト対象の項目、カテゴリー
水準:因子の取りうる値
強さ:因子の組み合わせ数
例えば、ブラウザにメッセージテンプレートを表示させるときの例
要件は
| 端末 | ブラウザ | テンプレート |
|---|---|---|
| iPhone | Chrome | 1 |
| android | safari | 2 |
| macbook | Firefox | 3 |
| windows | Edge | 4 |
この例では因子が端末、ブラウザ、テンプレート
水準がiPhone,android,macbook,windowsなど
強さは組み合わせ数なので、2の場合は(端末,ブラウザ)、3の場合は(端末,ブラウザ,テンプレート)
4.2.2 PICT
ペアワイズ法によってテストケースを生成するためのオープンソース・ソフトウェア
使い方は以下が詳しそう https://qiita.com/greymd/items/ad18aa44d4159067a627
まとめ
複数の要因に倫理関係がない場合。すなわち要因が直交している場合のテスト技法について。
- HAYST法
- テスト対象のテスト条件(HAYST法では「因子」と「水準」と呼ばれる要素を使います)を抽出し、これらの組み合わせを網羅するための直交表という表に割り付け、それをもとにテストを実施する技法
- 組み合わせるべき因子を抽出する方法について
- 有効な因子と水準の見つけ方
- ペアワイズ
- 因子の組(ペア)に注目して、全ての因子の組み合わせでなく、全てのペアの組み合わせにテストを制限
- PICT
5章 時間を網羅する
普段まったく問題なく動作しているソフトウェアが何気ないタイミングで動かなくなる問題について、状態遷移の観点と並列処理の観点からテストによる対応を考える。
5.1 状態遷移テスト
浅く全体を確認するテストから深く詳細にテストするものがある。
時間を意識したテスト設計について考える
状態遷移テスト
状態遷移図を書いてみる→状態遷移図から、適用不可のイベントを見つけることは困難。
状態遷移表を書き、適用不可(N/A)を含め、セルの一つひとつの動作をテストすることで基本的な状態遷移のテストを実施することができる。
Nスイッチカバレッジ
壊れた内部的な問題の顕在化方法について考える。 テストを確実に漏れなく実施するテスト技法は?→Nスイッチカバレッジ
Nスイッチカバレッジとは、 最初に遷移前の状態を列方向に、遷移後の状態を行方向にならべた状態遷移表を作成する。
状態遷移テストの実際
技法は上記の通りだが、実際の製品に適用しようとした瞬間に困難にぶつかる。
- ハードウェアの状態
- ソフトウェアの状態
- 外の世界の状態
に分けて考える
組み合わせテストの延長線上として捉えることができる。(HAYST 法やペアワイズでテストする)
テストだけではなく、アーキテクチャや設計、開発段階でのモデルチェッキングなどを総動員して対処する必要がある
6章 多次元の品質
人間の構造は現有のどのようなソフトウェアよりも複雑な構造をもっている。 ソフトウェアより複雑な構造をもつ人間のテストについて考えてみればソフトウェアテストへの糸口が見つかるかもしれない。
人間に対するテストとソフトウェアテスト
人間のテストというと学校で受けたテスト、すなわち、日々のテスト、中間試験、期末試験。身体測定、体力測定、健康診断など
人間に対するテストとソフトウェアテスト
| 人間に対するテスト | ソフトウェアテスト | ||
|---|---|---|---|
| 種類 | 目的 | 種類 | 目的 |
| 小テスト・中間テスト・期末テスト | 新たに学習した範囲を中心にしたテスト | 派生開発テスト テストレベル | 追加開発を中心にテスト 段階的テスト |
| 科目ごとのテスト | それぞれの分野の能力を確認 | テストタイプごとのテスト | ソフトウェアの特性を中心のテスト |
| 身体測定 | 大まかな発育状態の確認 | 静的テスト | コード量や複雑度などを静的にテスト |
| 小テスト・中間テスト・期末テスト | 新たに学習した範囲を中心にしたテスト | 派生開発テスト テストレベル | 追加開発を中心にテスト 段階的テスト |
| 体力測定 | 運動能力を結果で測定 | 動的テスト | 動かしてみて振る舞いを確認するテスト |
| 健康診断・人間ドック | 病気の有無を予測しながら確認 | テスト専門者によるテスト | バグの検出と品質の確認 |
テストの効率性
ソフトウェアテストにおいても経済的に実施することはもちろん、ツールを整備し簡単に多くの情報を取得できるようにすべき
ソフトウェアテストとは何か
点にはじまり、線、面、立体、時空とテストの複雑度を増やしてきた。 人間に対するテストと比較することで、適切な時期に適切なテストを行うことが大切。
テスト対象は一般的に複雑なので、さまざまな視点から眺めるということをする。 さまざまな視点から眺めるということは多次元である。
一つの方向から眺めただけでは、決してその姿は想像できない。
さまざまな視点でテスト対象をテストすることが重要
- シナリオテスト
- わざとちょっと変わった行動や失敗を犯すシナリオをつくり、そこから回復させながらユーザーのしたいことを継続させるようにする
- 視点の爆発を狭く深く追うことでカバー
- When,Where,Whoを明確にする
- 固定名詞や定数値を使う
- 例外処理シナリオ
- 受け入れテスト
- 受け入れるユーザー側でのテスト
- サンプリングテスト
- 品質を保証する
- 統計的テスト
- 信頼性を確認するための統計的テスト
最後に(まとめと感想)
テスト技法の奥深さを感じました。
テスト技術者のものの見方とは、「部分的ではなく全体・包括的に複数を捉えること、手段ではなく目的に目を向けること、企業ではなくお客様の目線で考えること、独立ではなく相互関連性を発見すること、構造に加え振る舞いを評価すること」
この一文が印象的でした。
今までテストについて真剣に向き合ったことがなくて、とりあえず書いてみるみたいなことをしていたので、テストを書くときに何を考えるか、とか仕様書の読み方はあまり意識していなかったなあ、と反省しました。
あと、PICTは実際に手を動かして使ってみました。
(テスト工数を半分以下に減らせそう...!)
テスト設計やったことなくて、テストってなんだろう?テスト設計って?な人は読んでみるのをおすすめします。
webpagetest.orgでGoogle MAPを計測
最適化グレード

すべてA
- LoadTime速い
- Document CompleteのBytes Inが少ない
- ページが読み込まれまでにブラウザがダウンロードしなければならなかったデータ量
- Document CompleteとFully Loadedに差が大きい
Waterfall View

- 1-2番目のリクエストでドキュメント本体と
/maps/_/js/k=maps.m.ja.D61iS2cbkq4.O/m=sc2,per,mo,lp,ti,ds,stx,bom,b/rt=j/d=1/rs=ACT90oGu35TczZS12uUzu-2-Uu94YaAN7wというjsを読み込んでいる。 このjsでDOMを生成しているっぽい(中身にdivやcssの記述があるので) - 3-23番目のリクエストで最初に表示される地図画像が読み込まれている。地図画像は正方形に分割されていて、最適化されている。合わせて
jsとfontも読み込まれている。おそらくjsは地図上に表示される座標データ - 24-30番目のリクエストで
manifest.jsonとGoogleのアイコン画像が読み込まれている。 - 31-48番目以降のリクエストで地図に必要なアイコン画像、記号画像などを読み込んでいる。
- 48番目以降のリクエストで初期に読み込まれた周りの地図画像や航空写真などを読み込んでいる
Connection View

Request Details

- Before On Loadが比較的少なくAfter On Loadが多い
- 初期表示に不必要な地図画像(周りの地図画像)は遅延読み込みしている
Dev tool Network



- Worker使っている
- gzip
cache-control: private, max-age=0- ブラウザにキャッシュさせるけど、変更ないか都度確認するようにしてる
- quic使用している。
- 最初の読み込みで必要最低限の画像を読み込んでいる
- スクロールすると画像が読み込まれている
コード


async- 非同期で実行しているjsが2箇所
- 直接
jsとcssを記述している- 最初に読み込む必要最低限なものだけ最初に読み込む
まとめ
初期表示を速くするために、必要最低限のリソースを最初に読み込み、スクロールして見える地図部分などは遅延読み込みをするように工夫し、最適化をしている。
ハイパフォーマンスブラウザネットワーキングを読みました(HTTP)
最近ハイパフォーマンスブラウザネットワーキングの10章~12章を読んだのでまとめました。
どんな本?
- ブラウザに関連する、インターネットで使用される様々なネットワーク技術をまとめたもの
- ハイパフォーマンスを誇るアプリケーションを構築するためには、なぜネットワークがそのような挙動を見せるのか理解する必要がある
- 「良い開発者はどのように動作するか知っている。素晴らしい開発者はなぜ動作するかを知っている」
- Webアプリケーションを提供するには、ブラウザとネットワークの動作の関連性について、硬い基盤となる知識が必要とされる
- ゴールはネットワークについてすべての開発者が知っておくべきすべてを説明すること
- どのようなプロトコルが用いられてる?
- どのような制限を持つ?
- アプリケーションをその基盤ネットワークに対して最適化する方法はどのようなもの?
- ブラウザにが提供するネットワーク機能とその使いどころは?
目的
ハイパフォーマンスを誇るアプリケーションを構築するために、なぜネットワークがこのような挙動なのかを理解し、理由が述べられるようになる。(なりたい...)
とりあえず10章~12章に絞って読みました。
10章 Web パフォーマンス入門
パフォーマンス最適化のプロセスの大部分は、システム内で明確に分離している。 制限と制約を持った各レイヤーの間に存在する相互作用を理解し紐解くこと。
すべての異なるレイヤーの相互作用を最適化すること?
相互依存しているいくつかの方程式を説いて回答を導き出すことではなく、場合によって多数の解が存在する。
それぞれのパフォーマンスのベストプラクティスを数値化・分析する前に一歩下がって、問題そのものを定義しておくことが重要。
- モダンWebアプリケーションとは?
- どのようなツールが利用可能なのか?
- Webアプリケーションをどのように計測するのか?
など
モダンWebアプリケーションの解剖学
モダンWebアプリケーションとは?
以下のサイトが参考になる。 主要Webサイトのコンテンツを自動分析してレポートしている。 https://httparchive.org/reports/state-of-the-web

webアプリケーションにはインストールプロセスがない。 URLを入力し、enterキーを押すだけで使える状態になる
最高のweb体験提供するには、数百のリソース、数MBのデータ、いくつもの異なるホスト。 これらすべてを数百ミリ秒以内に。
スピード、パフォーマンス、そして人間の知覚
生活のペースが歴史上一番早くなっている。 にもかかわらず、反応時間は常に一定。
アプリケーションが瞬時に反応したと感じさせられるためには、ユーザの入力に対して知覚できるレスポンスを数百ミリ秒のうちに提供しなければならない。
一般的なWebページのリクエストにかかるDNSルックアップ、TCPハンドシェイク、Webページリクエストに通常かかるいくつかのパケット往復時間を合計してみる
100-1000ミリ秒というレイテンシの予算はネットワークオーバーヘッドだけで、すべてではないにせよ、その大半が簡単に消化せれてしまう。
リソースのウォーターフォールチャートを分析する
Webパフォーマンスの議論はリソースのウォーターフォールチャートに言及するまで完結しない。
ウォーターフォールチャート → 増減を表すのに便利なグラフ
WebPageTestを使って診断する。
repro.ioの測定結果
Waterfall View

- fontの読み込みが多い印象
- jsの読み込みが多い印象

- ドメイン数多い印象

- DNS Lookup
- Initial Connection
- TCP接続の確立
- SSL Negotiation
- SSLを介してリソースをセキュアに読み込んでいる場合、ブラウザがその接続を確立している時間
- Time to First Byte
- リクエストがサーバーに送られ、サーバーがそれを処理して、必要な情報を送信し始め、レスポンスの最初の1バイトがブラウザに届くまでにかかる時間
パフォーマンスの柱:演算、レンダリング、ネットワーク
webプログラムの実行の主要なタスク
- リソースの取得
- ページのレイアウトとレンダリング
- JavaScriptの実行
レンダリングとスクリプトの実行モデルはシングルスレッド、インターリーブ型 同時並行して変更を加えることはできない
早く効率的なネットワークリソースの配信がブラウザで動作するすべてのアプリケーションのパフォーマンスにおいて必要
より大きい帯域幅は効果なし
動画よりもはるかに小さいWebアプリケーションがなぜ難題?
パフォーマンスのボトルネックとしてのレイテンシ
SPDYプロトコルの作者の一人、Mike Belsheによる定量的調査
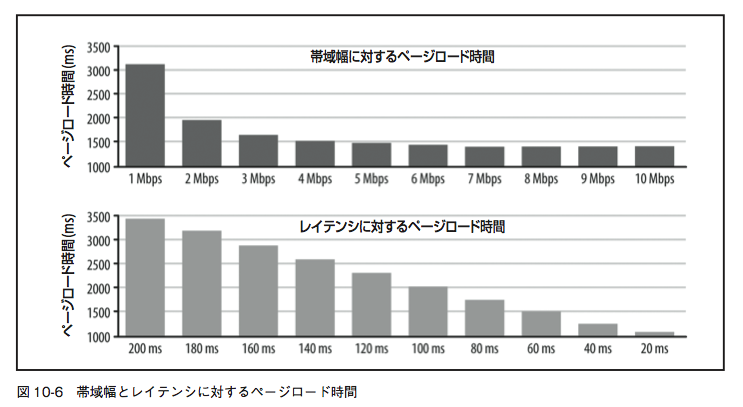
一般的にインターネットをスピードアップするには、
- RTT(Round-Trip Time) を下げる方法を探すべき
- ページロードに必要とされるパケット往復の数を減らすこと
レイテンシ データ転送における指標のひとつで、転送要求を出してから実際にデータが送られてくるまでに生じる、通信の遅延時間のことをいいます。 この遅延時間が短いことをレイテンシが小さい(低い)、遅延時間が長いことをレイテンシが大きい(高い)と表現しています。
RTT(Round-Trip Time) 通信相手に信号やデータを発信してから、応答が帰ってくるまでにかかる時間。
ブラウザ最適化
パフォーマンスはブラウザベンダにおける最も重要な競争力の要素であり、ネットワークパフォーマンスがその重要な基準であれば、ブラウザが日々進化していることに驚くべきことではない。
ブラウザ最適化は2つの大きなカテゴリに分類される
- ドキュメント認識最適化
- 投機的最適化
- DNSの事前開発やホストへの事業接続を行い、ユーザーが行う可能性が高いアクションを予測する投機的最適化を行う
↑の最適化はユーザや開発者の代わりにブラウザが自動的に行う
内部的にこれらの最適化がどのように、なぜ行われているのかの理解が大切
開発者はどのようにブラウザを補助できるのか?
最初に、ページの構造と配信によく注意を払う
- CSSやJavaScriptのような重要なリソースはドキュメント上で可能な限り発見できるべき
- レンダリングとJavaScriptの実行をブロックしないために、CSSは可能な限り早く配信されるべき
- 重要度の低いJavaScriptはDOMとCSSOMの構築をブロックしないように後回しにすべき
- HTMLドキュメント上はサーバに徐々に解析されるため、ドキュメントはサーバ上で生成された次第、部分的にも随時送信されるべき
dns-prefetch
<link rel="dns-prefetch" href="//somewidget.example.com">
DNS事前解決
外部URLからリソースを取得する要素がある場合、ブラウザはdocumentの上部から解釈し、外部URLを見つけた時点で外部URLへリクエストを送ります。この時に、前もって名前解決を済ませておけば、どこにリクエストするのかがわかっているから処理するのが早い
subresource
<link rel="subresource" href="/css/style.css">
重要度は高いがページの後ろで読み込まれるリソースの優先プリフェッチ
subresourceは同一ページ内で使用する任意のリソースを裏で読み込んでおくことができる。
prefetch
<link rel="prefetch" href="//example.com/future-image.jpg">
リソースのプリフェッチ
ユーザーが次に訪問する可能性が高いページを開発者がわかっている場合、リソースを前もって取得しておくことができる。ただし、JSやCSSなどキャッシュ可能なリソースに限られる。
prerender
<link rel="prerender" href="//example.com/future-page.html">
指定ページのプリレンダリング
指定したページのCSSを読み込み、JSを実行、ページ全体の不可視バージョンを作成する。
10章まとめ
DNS、TCP、SSLの遅延はほとんどのユーザと、Web開発者にはまったく透過的で、ネットワーク層で処理される。 ブラウザがこれらの往復を予測することを補助することによって、これらのボトルネックを排除しより速くより良いWebアプリケーションにつながる
11章 HTTP1.x
HTTP1.0の最適化はHTTP1.1にアップグレードすること この標準は多くの重要なパフォーマンス強化や機能を追加した
- 接続の再利用を可能とする、永続的接続
- レスポンスのストリーミングを可能とするチャンク化された転送エンコード
- 並列リクエストの処理を可能とするリクエストパイプライン
- リソース要求のバイトレンジ指定を可能にするバイト単位の転送
- 改善され、より効果的にしていされたキャッシュメカニズム
永遠の最適化項目
- DNSルックアップを減らす
- ルックアップ中はリクエストがブロックされる
- HTTPリクエスト数を減らす
- ページから不要なリソースを排除
- CDNを利用
- データを地理的に近い場所に配置することでTCP接続のネットワークレイテンシを劇的に減らせる
- Expiresヘッダを追加し、ETagを設定
- 同じリソースの取得のために何度もリクエストを送信しないように必要なリソースはキャッシュのしておくべき
- リソースをGzip圧縮する
- HTTPリダイレクトを避ける
HTTP1.1で追加されたパイプラインは実質的には失敗しており、基礎に亀裂を生じさせている 常に独創的であり続けるWeb開発者コミュニティが数々の自家製の最適化を発明 (ファイル結合、スプライト、インライン化)
しかしこれらの技術はHTTP1.1の制限を回避する一時しのぎのためのもの 本来はこのような最適化を気にすべきではない
キープアライブ接続の利点
HTTP1.1の主要なパフォーマンス向上の一つが持続的接続な接続、または、キープアライブ接続の採用
なぜこの機能がパフォーマンス戦略における重要な要素なのか?
キープアライブ
一つのTCP接続を一回のHTTP通信で切断せず、複数のHTTPリクエスト/レスポンスを送受信するよう維持する機能。
言うまでもなく、すべてのアプリケーションにとって持続的なHTTP接続は重要な最適化
HTTPパイプライン
HTTPパイプライン
一つのTCPコネクション上で、複数のHTTPリクエストを応答を待つことなく送信する技術である。 リクエストをパイプライン化することにより、ウェブページの読み込みが大幅に高速化される。
リクエストを早いうちに送信しておくことによって、それぞれのレスポンスをブロックすることなくもう一往復分のネットワークレイテンシを削減できる
しかし、HTTP1.1では多重化送信がサポートされていいないため、パイプラインはHTTPサーバや中間装置、そしてクライアントに様々な微妙かつドキュメント化されていない影響を及ぼす
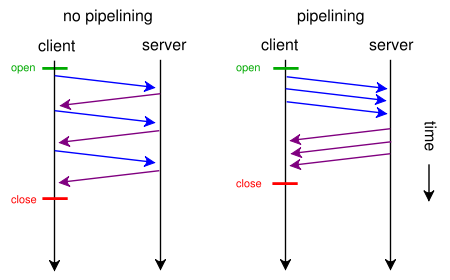
しかし、パイプラインはサーバー側できちんとした対応がされていないと、ブラウザ側のリクエストを正しく処理できないということになり実装にも課題がありました。さらに、HTTPパイプラインには「サーバーはリクエストの順番通りにレスポンスを返さなければならない」という制限があります。
5個あるリクエストのうち1番目のリクエスト処理が遅い場合、2個目以降のレスポンスは待ち状態(ヘッドオブラインブロッキング)になり結果全体の速度が遅くなるといった課題がある。このような状況から、パイプラインはOPERAブラウザを除きほとんどのモダンブラウザはデフォルトでOFFになっており、残念ながらほとんど利用されていないのが現状。
- 遅いレスポンスが一つ存在すると、その後のすべてのリクエストがブロックされる
- 並列処理を行う際、サーバはパイプライン化されたレスポンスをバッファリングする必要があり、サーバのリソースを圧縮する可能性がある。
- レスポンスに失敗するとTCP接続が終了する場合があり、クライアントは未処理リクエストを再送して重複処理になる可能性がある
- 中間装置が存在する可能性がある場合、パイプラインの互換性を信頼できる形で検出することは難しい。
- 中間装置にはパイプラインをサポートしないものがあり、接続切断する可能性がある、
↑のような複雑さと、発生する問題に対する指針がHTTP1.1標準で示されてないために、ある程度の改善効果が見込めるにも関わらずHTTPパイプラインはほとんど採用されていない
複数のTCP接続を使用する
モダンブラウザでは、デスクトップでもモバイルでも、ホストあたり6接続まで並列使用できる。
なぜ?
接続数が多いほどクライアントとサーバのオーバヘッドは増大するが、リクエストの並列性による利点は増す。 ホストあたりの6接続はバランスをとった。
オーバーヘッド
付加的に発生した処理(負荷)のこと
ドメインシャーディング
シャーディング(分割)
HTTP1.xプロトコルが持つ欠如のために、ブラウザベンダは1ホストあたり6つまでのTCPストリームを管理する接続プールの採用と維持を強いられてきた。
HTTPArchiveによると、平均的なWebページは90以上のリソースで構成されている。 これらのリソースがすべて同じホストから配信されている場合は相当なキューイング遅延が発生。
すべてのリソースを同じホストから配信しなければならない?
すべてのリソースを同じホスト(www.example.com)から配信する代わりに{shard1, shardN}.example.comといった複数のサブドメインにシャーディング(分割)できる。
接続先のホスト名が異なるので
- ブラウザの接続制限を増加させてより高いレベルの並列性を手に入れることができる。
- より多くのドメインに分割することで、より並列性が高まる。
デメリット
- それぞれのホストについてDNSルックアップが必要になる
- サイト管理者がリソースをどのように分割配置するかを管理しなければならない
実際にはドメインシャーディングは過度に利用される傾向があり、数十の利用されていないTCP接続を低下させてしまう。 HTTPSを使用しなければならない場合はTLSハンドシェイクのために追加のパケット往復が発生し、更にコストが高くなる
まとめ
ドメインシャーディングの実施に際して以下を考慮する必要がある
- まずTCPの最適化
- ブラウザは6つまでの接続を自動的に開始
- それぞれのリソースの数、サイズ、そしてレスポンス時間がシャードの最適数を左右する
- クライアントレイテンシと帯域幅がシャードの最適数を左右する
- ドメインシャーディングはDNSのルックアップとTCPスロースタートによってパフォーマンスを低下させる可能性がある
ドメインシャーディングは合理的ですが、不完全な最適化。 まずリソースの数を減らしてリクエスト数を削減することで大きな利益を得ることができる。
プロトコルオーバーヘッドの計測と制御
HTTP1.0はリクエストとレスポンスのヘッダに書式を追加しメタデータの交換ができるようにプロトコルを拡張した
ブラウザが開始するHTTPリクエストじゃ500-800バイトのHTTPのメタデータを運んでいるい。 すべてのHTTPヘッダは無圧縮のプレーンテキストで送信されるため、すべてのリクエストで高いオーバーヘッドにつながる可能性がある。
無圧縮で繰り返し送信されるヘッダの転送量を減らすことで、パケット往復によるネットワークレイテンシを削減でき、パフォーマンス向上に繋がる。
ファイル結合とスプライト
リクエスト数を減らすことは、使用プロトコルやアプリケーションに関係なく最高の最適化。
リソースを一つのリクエストにまとめる
ファイル結合 複数のJavaScriptやcssファイルを一つのリソースにまとめること
スプライト 複数の画像を統合した画像
デメリット
複数の独立したリソースのバンドルはキャッシュのパフォーマンスやページの実行速度を低下させる。
- 統合されたファイルは、現在のページには必要ないリソースを含んでいる可能性がある
- どれか一つのファイルをアップデートするとキャッシュは無効化され、リソースのバンドルを再度ダウンロードする必要があり、オーバーヘッドが追加発生する
- JavaScriptとCSSはどちらも、転送が終了してから構文解析を開始し、実行する。したがってアプリケーションの実行を遅くする可能性がある。
まとめ
結合とスプライトはHTTP1.xプロトコル向けのアプリケーション層における最適化。 正しく使用された場合はかなりのパフォーマンス向上をもたらすが、アプリケーションの複雑さやキャッシュ時の注意、アップデート時のコスト、スクリプト、レンダリングの実行時間に悪い影響を与える可能性がある。
- アプリケーションは多くの小さなリソースのダウンロードによってブロックされているか?
- アプリケーションは特定のリクエストを結合することで利益を得ることができるか?
- キャッシュの粒度が落ちるとアプリケーションに悪い影響があるか?
- 結合された画像は高いメモリオーバヘッドに繋がるか?
- 実行が遅くなることで最初のレンダリングまでの時間に影響を与えるか?
リソースインライン化
ドキュメントに直接リソースを埋め込むことにより、リクエストの数を減らす
data:image/gif;base64,R0lGODlhAQABAAAAACw=
dataURIスキームを利用すれば、画像や音声、PDFファイルを埋め込める
dataURIは小さくて、汎用的ではないリソースに向いている。 インライン化されるとブラウザやCDNにキャッシュされない
リソースをインライン化する大まかな指針としては、リソースの大きさが2KB未満程度であること。
検討すべき基準は以下
- ファイルが小さく、特定のページにのみ配置される場合は、インライン化を検討
- ファイルが小さく、多くのページで再利用される場合は、バンドル化を検討
- ファイルが小さくても頻繁にアップデートされる場合は個別ファイルのまま扱う
12章 HTTP2.0
HTTP2.0はアプリケーションをより速く、よりシンプルに、そして堅牢にする
HTTP2.0の目標は、リクエストとレスポンスの多重化によるレイテンシの削減、HTTPヘッダフィールドの効率的な圧縮によるプロトコルオーバーヘッドの最小化、リクエスト優先度設定とサーバプッシュの実現
HTTP2.0はHTTPメソッド、ステータスコード、URI、などすべてのコアコンセプトを全く変更しない。
目的は最高のパフォーマンス
HTTP2.0の歴史、そしてSPDYとの関係。
SPDYはHTTP2.0ではない。 HTTP-WG内の様々な議論を経てSPDYがHTTP2.0の出発点に採用される
設計と技術的目標
HTTP1.xは実装のシンプルさを意識して設計される。 しかし残念ながら、実装のシンプルさによってアプリケーションのパフォーマンスが犠牲になる。
HTTP2.0はこの犠牲を取り戻すよう設計されている。
バイナリフレーミングレイヤー
HTTP2.0のすべてのパフォーマンス強化の中心となる存在は、バイナリフレーミングレイヤー。
ストリーム、メッセージ、フレーム

ストリーム
確立した接続内の双方向のフレームの流れ
メッセージ
フレームの完全なシーケンス。論理的なメッセージを構成する。
フレーム
HTTP2.0における通信の最小単位。それぞれのフレームはヘッダを持ち、ヘッダは最低でもそのフレームが所属するストリームを識別する

リクエストとレスポンスの多重化
HTTPメッセージをフレームに分割し、インターリーブし、相手側で再構成を行う一連の機能は、HTTP2.0において最も重要な強化ポイント
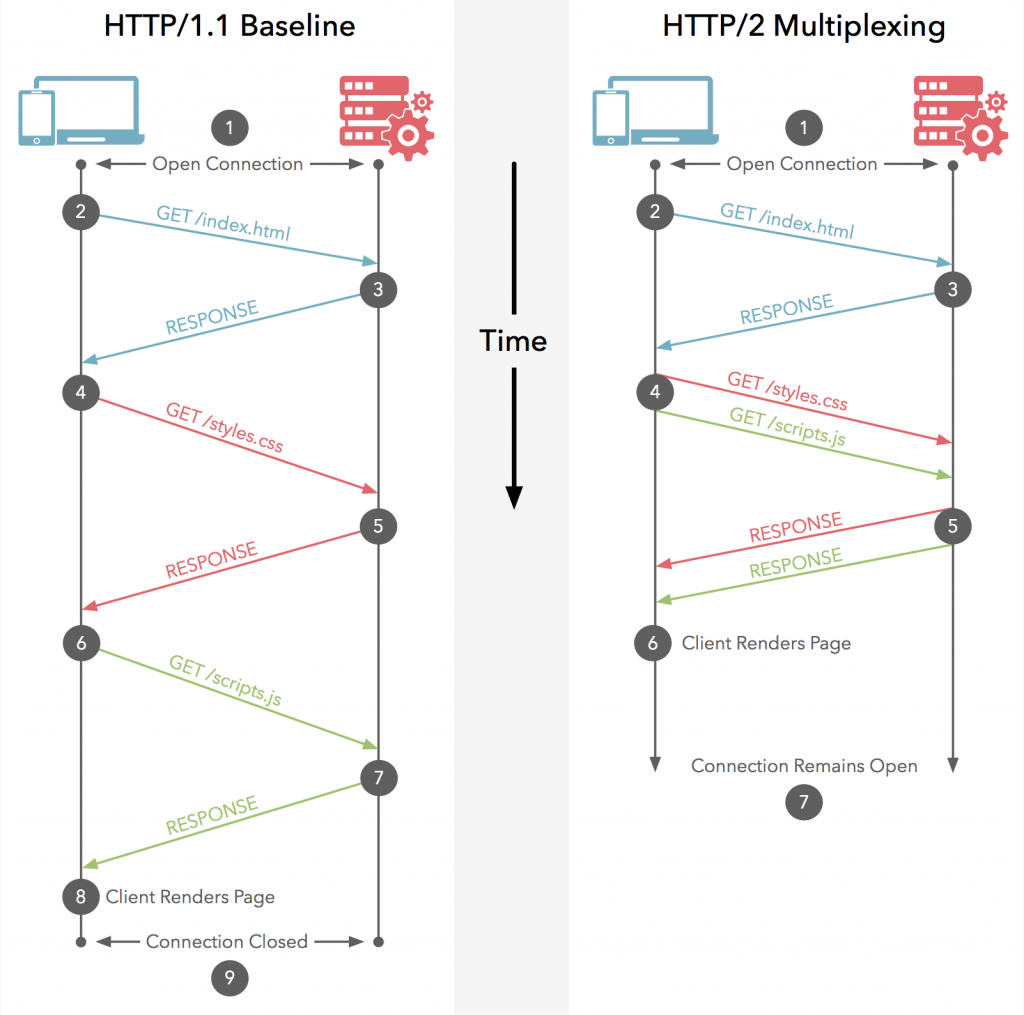
HTTP/2では1つの接続上にストリームと呼ばれる仮想的な双方向シーケンスを作ること(ストリームの多重化)で問題を克服している。
リクエスト優先度付け
HTTP2.0は優先度の扱いについてのアルゴリズムを指定していない。 ただ、優先度付けが行われたデータをクライアントとサーバ間でやり取りできるメカニズムを提供しているだけ。
クライアントは適切な優先度データを送信すべきで、サーバはその優先度に従って処理と配信を行うべき。
フロー制御
ひとつのストリームがリソースを占有してしまうことで、他のストリームがブロックしてしまうことを防ぐこと
サーバプッシュ
クライアントのリクエスト一つに対してサーバが複数のレスポンスを返すことができる
リソースはドキュメントの構文解析を行うことによって発見されるが、あらかじめサーバからプッシュしてもらう
ヘッダ圧縮
ヘッダのメタデータを圧縮。
効率的なHTTP2.0アップグレードと発見
HTTP2.0のサーバサポートについて情報が存在しない場合、クライアントはHTTPアップグレードを使用して適切なプロトコルのネゴシエートを行う。
このアップグレードを利用して、サーバがHTTP2.0に対応していない場合はHTTP1.1のレスポンスを返します。
まとめ
最高のパフォーマンスのために、「フレーム」という層を新しく設ける そのためにHTTP メッセージをテキスト→バイナリに
その結果 1つの接続上にストリームと呼ばれる仮想的な双方向シーケンスを作ること(ストリームの多重化)でパフォーマンス(レイテンシの改善がされた)が向上。
最後に(まとめと感想)
HTTP Archiveを眺めてると、モダンなwebアプリケーションを見てみるとリクエスト数やファイルサイズの年々増加していることが分かりました。
現在の平均的なWebアプリケーションは約1.8MBのサイズ、約70以上の従属リソースで構成されています。
また、サイトパフォーマンス向上のため多くのWeb開発者が数々の最適化(ファイル結合、スプライト、インライン化)を行っていますが、一時しのぎのためのものであって、本質的な解決策ではないです。
このような背景から、近年のモダンwebアプリケーションにおいて、HTTPのあるべきを考え、HTTP2が開発されたのでは? と読んでて思ったり。
HTTP2を使えば以前は不可能だった多くの最適化が可能になると思っていたのですが、QUICやHTTP/3の使用策定が行われているという話を聞き、 QUICやHTTP/3の話にも興味を持ちました。(これからどうなっていくのだろう...?)
参考

ハイパフォーマンス ブラウザネットワーキング ―ネットワークアプリケーションのためのパフォーマンス最適化
- 作者:Ilya Grigorik
- 発売日: 2014/05/16
- メディア: 大型本
はじめてのコンパイラ
ブラウザの仕組みを勉強したのですが、言語処理系の部分やコンパイルの仕組みが気になったので、 コンパイルの仕組みを調べてみました。
具体的には、 the-super-tiny-compilerのコードリーディング、写経を行い実際にブラウザで動かしてみて、コンパイルの仕組みを調べてみました。
今回の記事は
- なぜthe-super-tiny-compiler?
- コンパイラの仕組み
- the-super-tiny-compilerのコードリーディング
について書いています。
the-super-tiny-compilerとは?
JavaScriptで書かれたコンパイラの主要部分が非常に単純化された例。
なぜthe-super-tiny-compilerを読む?
コンパイラは身の回りにたくさんあるし、多くのツールはコンパイラのコンセプトを取り入れているのでthe-super-tiny-compilerを読むことで良い経験になるかなあと思いました。
どんなものを作る?
Lispのような関数呼び出しをCのような関数呼び出しにコンパイルするものを作成します。
| LISP-style | C-style |
|---|---|
| (add 2 (subtract 4 2)) | add(2, subtract(4, 2)) |
Stages of a Compiler
ほとんどのコンパイラは、解析、変換、およびコード生成の3つの主要な段階に分類されます。
- 構文解析は生のコードを受け取り、それをコードのより抽象的な表現に変換します。
- 変換はこの抽象表現を受け取り、コンパイラーが望んでいることを何でもするように操作します。
- コード生成はコードの変換された表現を受け取り、それを新しいコードに変えます。
Parsing(解析)
構文解析は通常、2つのフェーズに分けられます。
- 字句解析
- 構文解析
字句解析(Lexical Analysis)
生のコードを受け取り、それをトークナイザー(またはレクサー)と呼ばれるものによってトークンと呼ばれるものに分割する。
トークンは、孤立した構文の一部を表す小さな小さなオブジェクトの配列
(add 2 (subtract 4 2))
↓
トークン
[
{ type: 'paren', value: '(' },
{ type: 'name', value: 'add' },
{ type: 'number', value: '2' },
{ type: 'paren', value: '(' },
{ type: 'name', value: 'subtract' },
{ type: 'number', value: '4' },
{ type: 'number', value: '2' },
{ type: 'paren', value: ')' },
{ type: 'paren', value: ')' },
]
構文解析
トークンを受け取り、抽象構文木( abstract syntax tree、AST)を作成します。 (構文の各部分およびそれらの相互関係を記述する表現に再フォーマットしている。)
抽象構文木(AST)
{
type: 'Program',
body: [{
type: 'CallExpression',
name: 'add',
params: [{
type: 'NumberLiteral',
value: '2',
}, {
type: 'CallExpression',
name: 'subtract',
params: [{
type: 'NumberLiteral',
value: '4',
}, {
type: 'NumberLiteral',
value: '2',
}]
}]
}]
}
Transformation(変換)
ASTを受け取り、変更を加えることができます。 ASTを同じ言語で操作することも、まったく新しい言語に翻訳することもできます。
Traversal(通過、横断する)
{
type: 'Program',
body: [{
type: 'CallExpression',
name: 'add',
params: [{
type: 'NumberLiteral',
value: '2'
}, {
type: 'CallExpression',
name: 'subtract',
params: [{
type: 'NumberLiteral',
value: '4'
}, {
type: 'NumberLiteral',
value: '2'
}]
}]
}]
}
↓ 以下のように通過します
Program - ASTのトップレベルから開始 CallExpression(add) - プログラム本体の最初の要素に移動する NumberLiteral(2) - CallExpressionのパラメータの最初の要素への移動 CallExpression(減算) - CallExpressionのパラメータの2番目の要素に移動する NumberLiteral(4) - CallExpressionのパラメータの最初の要素への移動 NumberLiteral(2) - CallExpressionのパラメータの2番目の要素への移動
Visitors
ツリーの各ノードにアクセスするには?
"visitor"オブジェクトを作成
var visitor = {
NumberLiteral(node, parent) {},
CallExpression(node, parent) {},
};
ASTを通過するときに、一致するタイプのノードに「入る」たびに、このvisitorメソッドを呼び出します。 ノードと親ノードへの参照も渡します。
- → Program (enter)
- → CallExpression (enter)
- → NumberLiteral (enter)
- ← NumberLiteral (exit)
- → CallExpression (enter)
- → NumberLiteral (enter)
- ← NumberLiteral (exit)
- → NumberLiteral (enter)
- ← NumberLiteral (exit)
- ← CallExpression (exit)
- ← CallExpression (exit)
- → CallExpression (enter)
- ← Program (exit)
"exit"で呼ぶ可能性があるので最終的には
var visitor = {
NumberLiteral: {
enter(node, parent) {},
exit(node, parent) {},
}
};
Code Generation(コード生成)
コードを新たに作成します。
これで完成です!
the-super-tiny-compilerのコードリーディング
Parsing(解析)
1-tokenizer.js
(add 2 (subtract 4 2)) をトークンにします。
↓
[
{ type: 'paren', value: '(' },
{ type: 'name', value: 'add' },
{ type: 'number', value: '2' },
{ type: 'paren', value: '(' },
{ type: 'name', value: 'subtract' },
{ type: 'number', value: '4' },
{ type: 'number', value: '2' },
{ type: 'paren', value: ')' },
{ type: 'paren', value: ')' },
]
数字や文字は1文字ではなく(123 456)の場合などが考えられるので以下の処理をします。
//数値が続く限り
while (NUMBERS.test(char)) {
value += char;
char = input[++current];
}
2-parser.js
1-tokenizer.jsでできたトークンをastにします。
[
{ type: 'paren', value: '(' },
{ type: 'name', value: 'add' },
{ type: 'number', value: '2' },
{ type: 'paren', value: '(' },
{ type: 'name', value: 'subtract' },
{ type: 'number', value: '4' },
{ type: 'number', value: '2' },
{ type: 'paren', value: ')' },
{ type: 'paren', value: ')' },
]
↓
ast = {
type: 'Program',
body: [{
type: 'CallExpression',
name: 'add',
params: [{
type: 'NumberLiteral',
value: '2'
}, {
type: 'CallExpression',
name: 'subtract',
params: [{
type: 'NumberLiteral',
value: '4'
}, {
type: 'NumberLiteral',
value: '2'
}]
}]
}]
};
walkという再帰関数でループしています。
Transformation(変換)
3-traverser.js
nodeにアクセスできるようにします。 astの配列を順番に見ていき、enterメソッド、exitメソッドがある場合は呼び出します。
function traverseArray(array, parent) {
array.forEach(child => {
traverseNode(child, parent);
});
}
4-transformer.js
3-traverser.jsを使って新しいastを作成します。
ast = {
type: 'Program',
body: [{
type: 'CallExpression',
name: 'add',
params: [{
type: 'NumberLiteral',
value: '2'
}, {
type: 'CallExpression',
name: 'subtract',
params: [{
type: 'NumberLiteral',
value: '4'
}, {
type: 'NumberLiteral',
value: '2'
}]
}]
}]
};
↓
newAst =
{
type: 'Program',
body: [{
type: 'ExpressionStatement',
expression: {
type: 'CallExpression',
callee: {
type: 'Identifier',
name: 'add'
},
arguments: [{
type: 'NumberLiteral',
value: '2'
}, {
type: 'CallExpression',
callee: {
type: 'Identifier',
name: 'subtract'
},
arguments: [{
type: 'NumberLiteral',
value: '4'
}, {
type: 'NumberLiteral',
value: '2'
}]
}]
}
}]
};
Code Generation(コード生成)
5-code-generator.js
新しいastを元に構文作成。
.mapで新しい配列を作成。.joinで配列の中身を連結させて文字列にしています。
"add(2, subtract(4, 2));"
実際にブラウザで動かしてみた
まとめ
実際に簡単な例のコンパイラをコードリーディングをしてみることで、コンパイルの仕組みを理解することができました。
ESlintとかBabelだったり、pug→htmlの変換も同じような流れなのかなと、思ったり...!
今度はRubyでつくるRubyも読んでみたいなあと思っています。
ブラウザのレンダリングの仕組み
「ブラウザを立ち上げてアドレスバーにURLを打ち込んでEnter押してからページが表示されるまでに (裏側で) 何が起こっているかわかる限り説明してみてください。」
っていう問題を先輩から出題されたのですが、上手く答えられず...
ブラウザのレンダリングについてWebフロントエンド ハイパフォーマンス チューニングを読んで勉強したのでそのmemoです。
1. レンダリングエンジン
| ブラウザ | レンダリングエンジン | JavaScriptエンジン |
|---|---|---|
| Google Chrome | Blink | V8 |
| IE | Trident | Chakra |
| Microsoft Edge | EdgeHTML | Chakra |
| Firefox | Gecko | SpiderMonkey |
| Safari | Webkit | Nitro(JavaScriptCore) |
Blink,WebKit,Geckoはオープンソースのレンダリングエンジン。 BlinkはWebKitをフォークして誕生。
ブラウザ内のコンポーネント
いくつかのソフトウェアコンポーネントによって構成されている。
知っておきたい2つの重要なコンポーネントは以下。
- レンダリングエンジン
- JavaScriptエンジン
レンダリングエンジンとは?
- HTMLの描画エンジン。
- Webページのレンダリングのみを担当。
- HTMLや画像ファイルやCSS、JavaScriptなどを読み取り画面上の実際のピクセルとして描画する。
JavaScriptエンジンとは?
- JavaScriptの実行環境を提供するソフトウェアコンポーネント。
- DOMツリー、CSSOMツリーなど内部のオブジェクト、APIに対してJavaScriptからアクセスできるようにバインディングを提供。
- ブラウザの拡張機能を実行するために利用される
CSSOMとは?
CSSOMは、CSS Object Modelを意味する略語であり、ブラウザでロードされたCSSのツリー構造を保持する仕組み。ブラウザは、このCSSのツリー構造をDOMに対して適用することで、上位のスタイルからより具体的な下位のスタイルへと連鎖的にスタイルを決定していく。
2. ブラウザのレンダリングの流れ
レンダリングの大まかな流れ
Loading(リソース読み込み)
↓
Scripting(JavaScript実行)
↓
Rendering(レイアウトツリー構築)
↓
Painting(レンダリング結果の描画)
4つの工程からレンダリングが始まって、最終的に描画されるまでをフレーム(Frame)と呼ぶ。
3. リソース読み込み
まず行われるのがリソース読み込み
ブラウザは、与えられたURLからHTMLを読み込んで、そこからさらにレンダリングに必要な付属するリソースを読み込んで解釈する このフェーズでは、次の2つの処理がある。
- リソースのダウンロード
- HTMLを含むリソースをサーバーからダウンロードする。
- リソースのパース
リソース
- HTMLファイル
- CSSファイル
- JS画像ファイル
3.1 リソース取得に用いるネットワークプロトコル
ブラウザは与えられたURLをもとにレンダリングをもとにレンダリングに必要なリソースを様々なネットワークプロトコルを通じて取得する。
ブラウザでよく利用されるネットワークプロトコルはHTTP
- URLに含まれるホスト名の解決
- HTTPによる取得
IP(Internet Protocol)
ネットワークのノード間のパケットのやり取りを中継するプロトコル。
HTTPでネットワーク越しにリソースを取得する場合、リソースの取得の速さはIPのパケットの届く速度に依存する。 →HTTPでやり取りされるデータパケット内に格納されるから。
パケット データの通信に利用される最小単位のデータ。 通信するデータの入れ物としてやり取りされる
TCP(Transmission Control Protocol)
TCPは、IPに対して以下のような機能を付加する上位プロトコル
- 相手先に確実にデータが届いているかどうか確認
- データの欠損や破損をけんちして再送
- データの送信順を保証する
TLS(Transport Layer Security)
与えられたURLのプロトコル部分がhttpsだった場合TCPとHTTPの間でTLSプロトコルを利用する。 TLSは一般にSSLと呼ばれる。
- クライアントとサーバーの認証機能
- 通信データの暗号化
- データの改ざんの検出
UDP (User Datagram Protocol)
IPに対して機能を付加。 TCPと似ている。 TCPプロトコルは、IPに対してデータの欠損の検知やデータの送信順の保証などにお信頼性のあるデータ通信を提供するがUDPではそのような機能は特に追加しない。
HTTP
DNS(Domain Name System)
TCP接続では、接続を開始するのに相手方のIPアドレスが必要。 ブラウザはURLに含まれているホスト名をIPアドレスに変換した上でHTTPリクエストをサーバーへと送信する。
DNSはホスト名に紐づくIPアドレスを検索するための分散システム。
4. それぞれのリソースの読み込み
ブラウザはホスト名の解決などを経て、HTML,CSS,JacaScriptや画像といったリソースを取得する。
一番最初に読み込まれるリソースはHTMLファイル。
- HTMLファイル内に記述されているリソースの参照があれば、さらにそのリソースを読み込む。
- 取得したリソースは、パースされてブラウザの内部表現に変換される。
HTMLの読み込み
- ブラウザは与えられたウェブページのURLを元にサーバーへHTTPリクエストを送信。 HTTPレスポンスとしてHTMLを取得する。
- 読み込んだHTMLを解釈してドキュメントのDOMツリーを構築する。DOMツリーへの変換過程の中でツリーに含まれる画像やCSSなどのドキュメントに紐づくリソースに取得や読み込みを行う。
- ブラウザは構築したDOMツリーを元にしてRenderingの処理を行う。
DOM(Document Object Model)
HTMLのドキュメントを表現するオブジェクト。 DOMツリーは、レンダリングエンジンが利用する木構造を持つ内部表現。

DOMツリーへの変換の工程
- 字句解析によるトークンのリスト化
- 構文解析による構文木構築
- 構文木内にあるJavaScriptを実行しつつDOMツリーの構築
字句解析
コンパイラーがソースコードを解析し、目的のプログラムを生成する際の処理工程のひとつ。字句解析は、ソースコードに記述された変数や定数などの値を実際の値に展開するまでを担当し、その結果を次の工程である構文解析に引きわたす。
トークン
1つの塊になっている文字列
CSSの読み込み
読み込まれたCSSは、レンダリングエンジンによってパースされてCSSOM(CSS Object Model)ツリーへと変換される。

DOMツリーと違ってCSSOMツリーの深さは可変ではなく、一定ですが、ルールセットが増えれば増えるほどDOMツリー内の要素に適用されるスタイル計算にかかる時間が大きくなる。
5. JavaScript実行 Scripting
リソースを一式読み込んだ後、JacaScript実行(Scripting)へ移行。
レンダリングエンジンは、JavaScriptのコードをJavaScriptエンジンに引き渡して実行させる。
JavaScript実行の流れ
(JavaScriptコード)
↓
字句解析
↓
(トークン列)
↓
↓
(抽象構文木)
↓
↓
(実行可能コード)
↓
実行
※JavaScriptエンジンの実装によって異なる。
JavaScriptの実行は、最初にJavaScriptファイルを読み込んだとき以外にも、DOMイベントが発火し、イベントリスナが起動するときに起こる。
5.1 字句解析と構文解析
JavaScriptエンジンは、与えられたコードを何らかの実行可能な形式に変換(コンパイル)した上でJavaScriptに書かれた処理を実行する。
コンパイルを行うために、JavaScriptのコードを抽象構文木(英: abstract syntax tree、AST)と呼ばれるコンパイル可能な形に変換する。 JavaScriptの場合はJavaScriptオブジェクト(JSON)として表現される。
抽象構文木
構文構造をデータ構造に起こしたもの。JavaScriptの文法に沿った形で表現される木構造のデータ。
抽象構文木
{ "range": [ 0, 10 ], "type": "Program", "body": [ { "range": [ 0, 10 ], "type": "VariableDeclaration", "declarations": [ { "range": [ 4, 9 ], "type": "VariableDeclarator", "id": { "range": [ 4, 5 ], "type": "Identifier", "name": "a" }, "init": { "range": [ 8, 9 ], "type": "Literal", "value": 1, "raw": "1" } } ], "kind": "var" } ], "sourceType": "module" }
5.2 コンパイル
JavaScriptエンジン内部のコンパイラは、先ほど構築した抽象構文木を実行可能な形式にコンパイルする。
スクリプト言語の言語処理系の実装の方法
JavaScriptエンジンで多いのは、JIT(Just In Time)コンパイル型の実装
5.3 実行
実行可能な形式にコンパイルされたJavaScriptのコードは、処理系内部の仮想マシン、もしくはCPUで実行される。
6. レイアウトツリー構築 - Rendering
JavaScriptの実行が終わると、レイアウトツリー構築(Rendering)が行われる。
具体的に以下
- スタイルの計算
- レイアウト
レイアウトツリー
ブラウザで DOM と CSSOM を組み合わせて、ページ上の表示可能なすべての DOM コンテンツと、各ノードのすべての CSSOM スタイル情報を取り込んだもの
6.1 スタイルの計算
DOMツリー内の全てのDOM要素に対して、どのようなCSSプロパティが当たるのか計算する。
CSSルールのマッチング処理
CSSOMツリーからCSSルールセットを走査、DOMツリーからDOM要素を走査。 どんなCSSルールが適用されるのかを計算する。
CSS セレクタのマッチング
body > .container > .button { ... }
- DOM要素のclass属性にbutton
- 親要素のclass属性にcontainer
- 親要素のDOM要素名がbody
レンダリングエンジンはセレクタを右から左に解釈してマッチング処理を行う
どのDOM要素に対してどのCSSルールセットが適合するかレンダリングエンジンには分かるようになる。
CSSルールセット
div.my-button, button { background-color: green; color: white; }
の{}部分
適用されるCSSプロパティの算出
DOM要素にどのCSSプロパティと値が適用されるのか算出する。
(margin, padding,positionの算出ではない)
詳細度の計算など
<p class="foo"> foo </p> .foo { color: red; } p { color: blue; }
.fooのスタイルが当たることの計算
6.2 レイアウト
DOM要素に当たるCSSプロパティを算出した後、レンダリングエンジンはDOMツリー内のすべてのノードの視覚的なレイアウト情報の計算、レイアウトを行う。
設計図的なもの
レイアウト情報
- 要素の大きさ
- 要素のmargin
- 要素のpadding
- 要素の位置
7. レンダリング結果の描画 -Painting
DOMツリーのレイアウト情報の算出が終わると、レンダリング結果の描画(Painting)。
レンダリングエンジンはユーザーが見ることができる実際のピクセルを描画。
3つの処理が行われている。
- ペイント(Paint)
- ラスタライズ(Rasterize)
- レイヤーの合成(Composite Layers)
最後のレイヤーの合成が終わることで、ユーザーの目にはレンダリングエンジンが描画した表示になる。
7.1 ペイント
内部の低レベルな2Dグラフィックエンジン向けの命令を生成。
- RenderTreeを元にDisplay Listと呼ばれる内部の低レベルグラフィックエンジンのための命令の列を生成。
組み込まれるグラフィックエンジンはブラウザの実装ごとに異なる
7.2 ラスタライズ
- 生成された命令を用いて実際にピクセルに描画する。
- レイヤーごとに一枚一枚描画される。
- レイヤーが生成されるのは、
positionやtransform,opacityなどのプロパティが適用されているとき
レイヤー単位でピクセルに描画するのはなぜ? 再レンダリングする場合、すでに描画が終わったレイヤーを再利用することで、素早く再レンダリングできる場合がある。
7.3 レイヤーの合成
ピクセルにしたレイヤーを合成して最終的なレンダリング結果を生成する。
CPU
コンピューター全体の計算処理
3Dグラフィックなどの画像描写に必要な計算処理
7.4 コンテンツの表示
レイヤーの合成の処理を終えてやっと
レンダリングエンジンがコンテンツを表示します!
8 再レンダリング
ユーザーやブラウザの何らかのアクションやJavaScriptのコードの実行やドキュメント内のイベントによってレンダリングは再度引き起こされる。
再レンダリングが引き起こされるのは?
- DOMイベントが発火するとき
「ブラウザを立ち上げてアドレスバーにURLを打ち込んでEnter押してからページが表示されるまでに (裏側で) 何が起こっているかわかる限り説明してみてください。」
はじめは、この質問を何も見ずに15分考えると、ぼんやりとした流れを説明することしかできなかったのですが、ブラウザの仕組みを勉強したあとは3倍くらいの量できちんと説明できるようになりました◎
参考
- https://ja.wikipedia.org/wiki/HTML%E3%83%AC%E3%83%B3%E3%83%80%E3%83%AA%E3%83%B3%E3%82%B0%E3%82%A8%E3%83%B3%E3%82%B8%E3%83%B3
- https://webukatu.com/wordpress/blog/928
- https://qiita.com/Tsuyoshi84/items/5575aff0408ea7e64e68
- https://kotobank.jp/word/%E5%AD%97%E5%8F%A5%E8%A7%A3%E6%9E%90-4120
- https://kotobank.jp/word/%E3%83%88%E3%83%BC%E3%82%AF%E3%83%B3-6633
- https://codingjp.com/web/6407/
- レンダリング ツリーの構築、レイアウト、ペイント | Web | Google Developers

- 作者:久保田 光則
- 発売日: 2017/05/26
- メディア: 単行本(ソフトカバー)
Vue.jsのリアクティブシステムみたいなのを作ってみた。
Vue.jsの中身を読んでみる!というのを最近やってみていて、算出プロパティ部分を読んでいたのですが、 実際に同じようなコードが書けないかなあと思い、少し書いてみました。
Vue.js 算出プロパティ部分のコード
Vue.jsでの実現方法は多分こんな感じ
initDataでobserveが呼ばれている
vue/state.js at dev · vuejs/vue · GitHub
function initData (vm: Component) { let data = vm.$options.data // ... data = vm._data = typeof data === 'function' ? getData(data, vm) : data || {} // observe data observe(data, true /* asRootData */) }
↓
observeはObserverオブジェクトを生成
vue/index.js at dev · vuejs/vue · GitHub
export function observe (value: any, asRootData: ?boolean): Observer | void { if (!isObject(value) || value instanceof VNode) { return } let ob: Observer | void if (hasOwn(value, '__ob__') && value.__ob__ instanceof Observer) { ob = value.__ob__ } else if ( shouldObserve && !isServerRendering() && (Array.isArray(value) || isPlainObject(value)) && Object.isExtensible(value) && !value._isVue ) { ob = new Observer(value) } if (asRootData && ob) { ob.vmCount++ } return ob }
↓
ObserverクラスでdefineReactiveが呼ばれてる。
export class Observer { value: any; dep: Dep; vmCount: number; // number of vms that have this object as root $data constructor (value: any) { this.value = value this.dep = new Dep() this.vmCount = 0 def(value, '__ob__', this) // ... walk (obj: Object) { const keys = Object.keys(obj) for (let i = 0; i < keys.length; i++) { defineReactive(obj, keys[i]) } }
↓
defineReactiveでObject.defineProperty を使用してリアクティブシステムを実現している...?
vue/index.js at dev · vuejs/vue · GitHub
Object.defineProperty(obj, key, { enumerable: true, configurable: true, get: function reactiveGetter () { const value = getter ? getter.call(obj) : val if (Dep.target) { dep.depend() if (childOb) { childOb.dep.depend() if (Array.isArray(value)) { dependArray(value) } } } return value }, set: function reactiveSetter (newVal) { const value = getter ? getter.call(obj) : val /* eslint-disable no-self-compare */ if (newVal === value || (newVal !== newVal && value !== value)) { return } /* eslint-enable no-self-compare */ if (process.env.NODE_ENV !== 'production' && customSetter) { customSetter() } // #7981: for accessor properties without setter if (getter && !setter) return if (setter) { setter.call(obj, newVal) } else { val = newVal } childOb = !shallow && observe(newVal) dep.notify() } })
自分で同じような仕組み書いてみる
Object.definePropertyを使用しているみたいなので調べてみました。
Object.defineProperty
あるオブジェクトに新しいプロパティを直接定義したり、オブジェクトの既存のプロパティを変更したりして、そのオブジェクトを返します。
実際に書いてみる
<html> <body> <ul> <li> <p>テキスト</p> <p id="message"></p> <input type="text" id="text"> </li> <li> <p>チェックボックス</p> <input type="checkbox" id="checkbox"> <label for="checkbox" id="label-checkbox"></label> </li> <li> <p>セレクトボックス</p> <select> <option disabled value="">Please select one</option> <option>A</option> <option>B</option> <option>C</option> </select> <p id="selectedText"></p> </li> </ul> </body> </html>[f:id:cidermitaina:20190128100626g:plain]
const data = {}; const p = document.getElementById('message'); const label = document.getElementById('label-checkbox'); const input = document.querySelectorAll('input'); const inputTypeText = document.getElementById('text'); const inputTypeCheckbox = document.getElementById('checkbox'); const select = document.querySelector('select'); const selectedText = document.getElementById('selectedText'); p.textContent = inputTypeText.value = 'Hello, World!'; label.textContent = inputTypeCheckbox.value = 'false'; selectedText.textContent = inputTypeCheckbox.value = 'selected'; // リアクティブプロパティの定義 Object.defineProperties(data, { message: { get() { return message; }, set(newVal) { message = newVal; p.textContent = message; } }, checked: { get() { return checked; }, set(newVal) { checked = newVal; label.textContent = checked; } }, selected: { get() { return selected; }, set(newVal) { selected = newVal; selectedText.textContent = selected; } }, }); input.forEach((el) => { el.addEventListener('input', (ev) => { data.message = ev.target.value; data.checked = ev.target.checked; }); }); select.addEventListener('change', (ev) => { data.selected = ev.target.value; });
以下のようになります。
