30歳の振り返り
上司との 1on1 で定期的に今後のキャリアについて聞かれることがあるのですが、毎回「キャリア... 難しいですね」、「上手く考えられないですよね…」って言葉で濁してしまいます。
そもそも自分の今までのキャリアってなんだろうと思い、自分のキャリアというか、人生を振り返ろうと思います。
書くことで今後の自分のキャリアを考える手がかりになればいいなあと思って。
今の自分なら昔の自分のことをどう思うか、社会人一年目から今の自分に手紙を書いてみようと思います。
22 歳の私へ
銀行の総合職での内定が決まってとても未来にわくわくしていますね。 入行前に資格をたくさん取らないといけないけれど、銀行員として働けることが嬉しく資格の勉強が捗っている気がしています。
この調子で頑張ってください。
23 歳の私へ
銀行でのお仕事が始まりましたね。
研修が終わり、後方業務ができるようになり、窓口に立てるようになりましたね。 同期の中では比較的はやく窓口業務をやらせてもらってると思います。 毎日夜にコツコツ振り返りをしているおかげだと私は思います。
ですが、とても大変そうです...
窓口に立つとお客さんに理不尽に怒鳴られたり、女子更衣室では悪口を言われたり。 毎日閉店後、支店長が自分の気に入らない部下に怒鳴っていますね。見ていられないですよね。 飲み会では、大人が大人をいじめていますね、支店長がセクハラをしていますね、みんな見て見ぬふりをしていますね。
自分のなりたかった大人ってどんな大人だっけ?
すごく良い問いかけだと思います。
24歳の私へ
こんにちは。お仕事辛そうですね。
でも最近リリースされた家計簿アプリをインストールして、口座と連携させたりして… とてもわくわくしていますね。良かったです。 「FinTech 系のアプリ画期的にです!」「銀行業務変わっていきそうですよね!」って話をしてもあんまり聞いてもらえなくてしょんぼりしていますが、元気を出してください。
そういえば、自分のなりたかった大人、やりたいことが決まったみたいですね。 エンジニアになるって聞いてすごく驚きました。コードなんて書いたことがないのに。 でも、昔からやるって決めたら頑固なところがあるので、止めても無駄ですよね。
家族に銀行をやめて、東京に行く話をしたらとても怒られましたね、二度と帰ってこなくていいみたいです。 辞める話をしてから支店長や事務長から冷たくされてますね。支店長や事務長の言っていることなんて気にしなくていいと思います。 彼氏にも振られたみたいですね。
今は辛いかもしれませんが、きっと東京での生活は上手くいくと思います。応援しています。
25歳の私へ
お元気ですか?東京での生活は慣れましたか?
未経験で制作会社に入社して、LPを作ったりコーポレートサイトを作成してるんですよね。すごいです。 この調子でいろいろな技術を身につけてみてください。自分の役に立つと思います。
だけど、友達もいないし、家族には連絡できないし、どこに行くのも一人で少し寂しそうです。
26歳の私へ
東京でのお仕事は慣れましたか?
コーディングができるようになってきたので、フロントエンドエンジニアとしてWebアプリ制作をできるようになりたいと思ってるのですね。
実際に転職してやりたいことを叶えようとしている実行力はとても素敵だと思います。
ですが、なかなか新しい会社に馴染めず、お仕事にもついていけず悩んでいるみたいです。
会社のエンジニアの男の人たちがなんでこの会社に入ったの?失敗だってコソコソ話をしていますね。
悩んでいることは素直に上司に話をした方がいいと思います。
お仕事についていくために毎日勉強をしているけど、頭がぼんやりしてあんまり内容が入ってこないみたいですね。 ちゃんとご飯を食べていますか?どんどん痩せていっている気がします。体重も30キロ代になっています。
無理はしないで、辛いときは辛いといった方がいいと思います。
27歳の私へ
お元気ですか?元気そうではないですね。
急に別のチームの男の先輩に二人きりで呼び出されて、能力がないからエンジニアを辞めた方がいい、開発チームには必要ないって言われましたね。 私はパワハラだと思います。すぐに上司に言った方がいいと思います。
でも怖くて言えなかったんですよね。自分には能力がないから、言われてしまうのが仕方ないことだと思ってしまって。
頼れる人もいなくて、ずっと抱え込んでしまっているの良くないと思います。 毎日死にたいと思ってるのも良くないと思います。
誰か頼れる人に話してみると良いかもしれません。
一人で東京にきて誰に話せばいいのか分からなくて、本当に一人なことに気づいてしまって、どうすればいいか分からなくて、私は見ていられないです。
28歳の私へ
お元気ですか?
転職を決意したみたいですね。しかもエンジニアとして。 エンジニアは向いていないかもしれないと、辞めてしまうのかと思っていました。 やっぱり昔から自分がやると決めたことに関しては頑固だなあと思います。
新しい会社はとても優しい人が多くて働きやすそうですね。良かったです。
ですが、大丈夫ですか?ちゃんとご飯を食べていますか? どんどん痩せてきている気がします。
コードを書いてると涙が出てきますね。MTGも人の声が怖くて、震えているときがあります。 能力がない、やめた方がいい、誰も言っていないのに聞こえる。
たぶん、それ病気です。 一人で頑張りすぎたんだと思います。
ゆっくり休んでください。
誰かに助けてって言えるようになれるといいですね。
29歳の私へ
お元気ですか?
少しお休みしたことで元気になっている気がします。
お仕事楽しくできるようになっていますね。安心して働けるチームメンバーで良かったです。 自信なさそうにしているけど、上手くやれてると思います。もっと自信をもってください。
フロントエンドエンジニアとしてWebアプリを開発するという目標は達成できているのではないですか?
30歳の私へ
新しいプロダクトを開発してリリースしたそうですね!すごいです! 新規プロダクトチームに異動するか悩んでいたけど、自信に繋がったのではないですか? もっと自信を持ってください。
今まで、苦手なことも頑張らないと認めてもらえないと思っていたけど、上司が変わり 1on1 で苦手なことに対して無理をしなくてもいいこと、無理をしなくても私を肯定してくれることに救われていますね。 そのままでも十分頑張れています。もっと自信を持ってください。
せっかく頑張れているのに、私は少し体が心配です。 心臓に病気が見つかりましたね。 同じ病気の人の手術やリハビリに関するブログを見て、病気が進行することが怖くなっているみたいですが、大丈夫です。
くよくよ悩みすぎず、毎日を一生懸命に生きてください。
たぶん心は一生不安です。 人生は一度きりです。
未来の私へ
こんにちは。 未来の私は自分に自信が持てていますか?
ここ何年かの私はずっと自分に自信が持てずに生きていて、とても生きづらいです。
もし未来の私が自信を持って生きているのなら、とても嬉しいです。
でも、未来の私なら大丈夫な気がします。
昔から自分で決めたことに関しては諦めず、やり切っていますよね。
キャリアも人生も不安だけど、未来の私ならきっと大丈夫です。応援しています。
Obsidian を手帳代わりに使ってみる
これは何
最近メモアプリを Obsidian に変えました。 いろいろなメモアプリを試しては、乗り換えるを繰り返していたのですが、ここ1年は Obsidian を使い続けていて、お気に入りなので、私の使い方を紹介します。
Obsidian とは?
使い方の紹介の前に Obsidian のざっくりとした説明です。
マークダウン形式のノートを作成、整理、参照するためのプライベートなノートアプリです。
デスクトップアプリなので、私は mac 用のものをインストールして使ってます。
お気に入りポイント
私のお気に入りポイントは以下です。
- シンプル
- ローカルに md ファイルが保存されていく
今までは Notion を使っていたのですが、できることがたくさんありすぎてどんな風に使っていくか、なかなか決められないことがストレスでした。 また、オンラインツールなので、ネットワーク接続が必要で動作が少し遅いことがやだなあと感じていました。
Obsidian はマークダウンエディタで、それ以上の機能はなく、UIも分かりやすいので使い勝手がとても良かったです。
ローカルで動作するため、ネットワーク接続が必要なく、さくさく動くところも嬉しいポイントです。
必要があれば md ファイルを他のツールに移行できるのも良いです。
実際に使ってみる
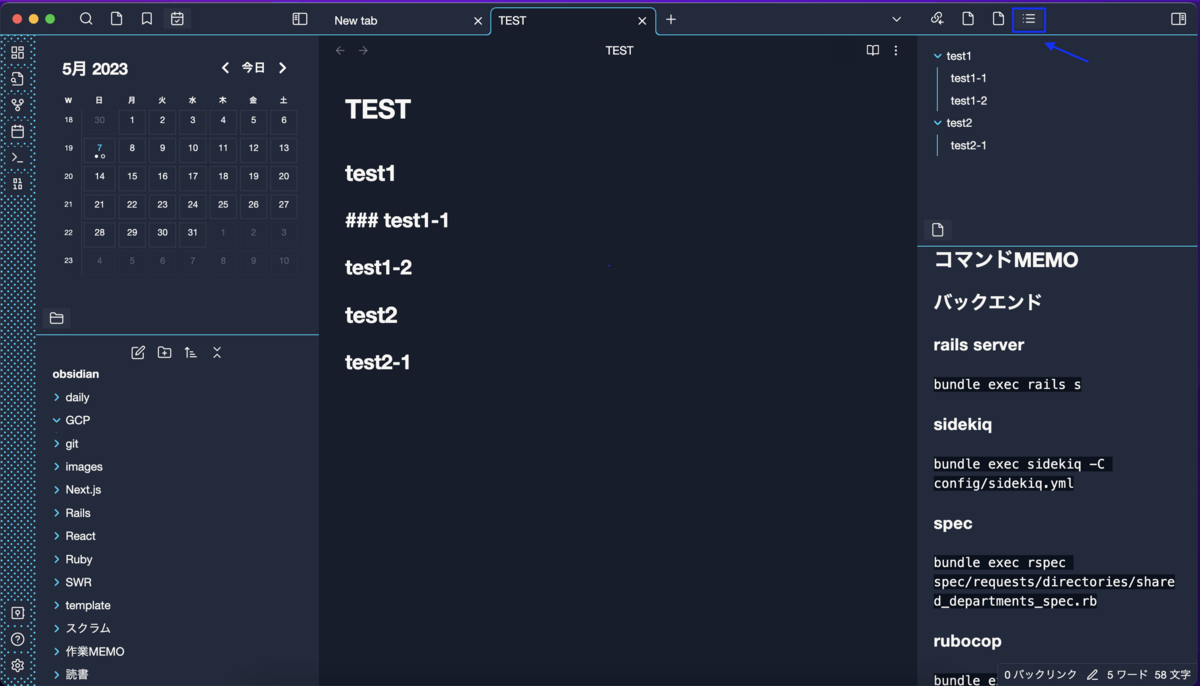
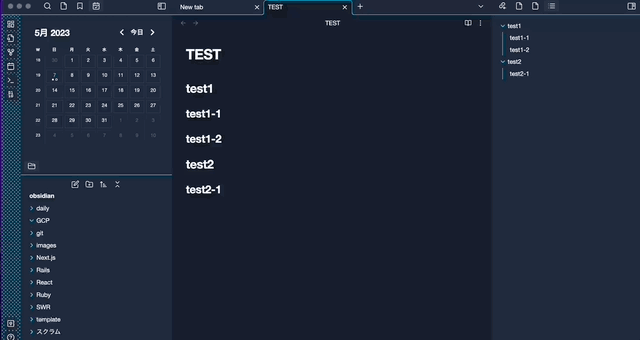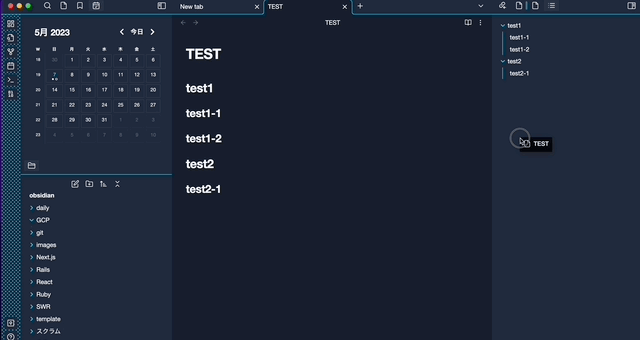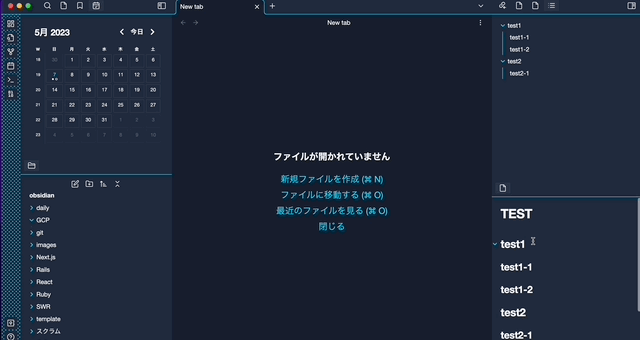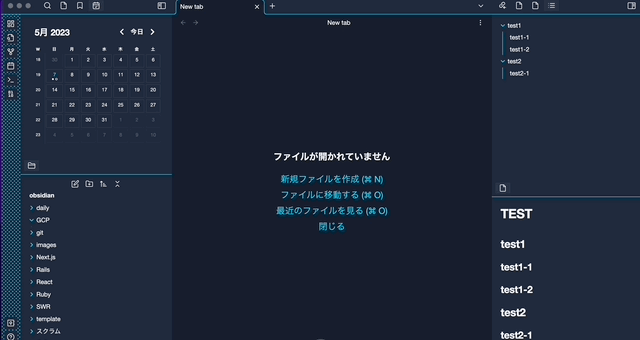
私の Obsidian の画面は↓な感じです。
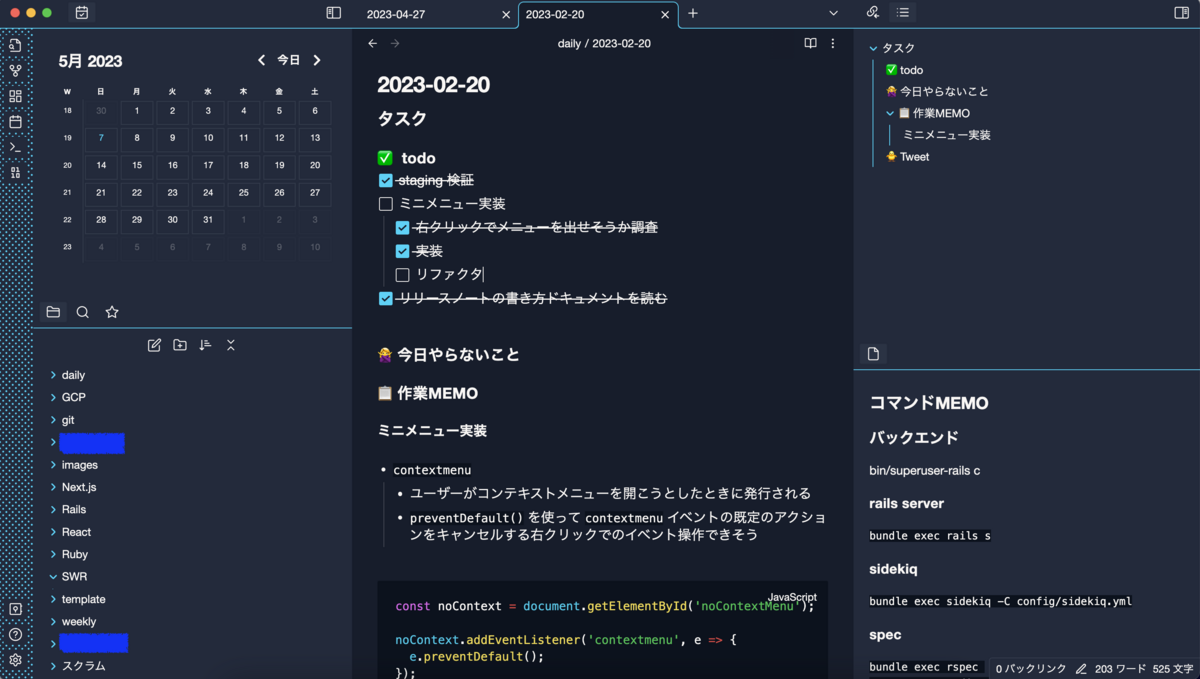
カレンダーを左に配置して、アウトラインを右上に、よく見るノートを右下に配置しています。
カレンダーの日付をクリックすると Daily notes を作成できたり、過去の Daily notes を見ることができます。
私は Daily notes をタスク管理、作業メモ、日記のような手帳のような感じで使用しています。
設定方法
1. カレンダーを表示させる
Daily notes 機能はデフォルトでONになっているので、まずはカレンダーを表示させるようにします。
カレンダーは 設定 > コミュニティプラグイン > 閲覧 をクリックし、
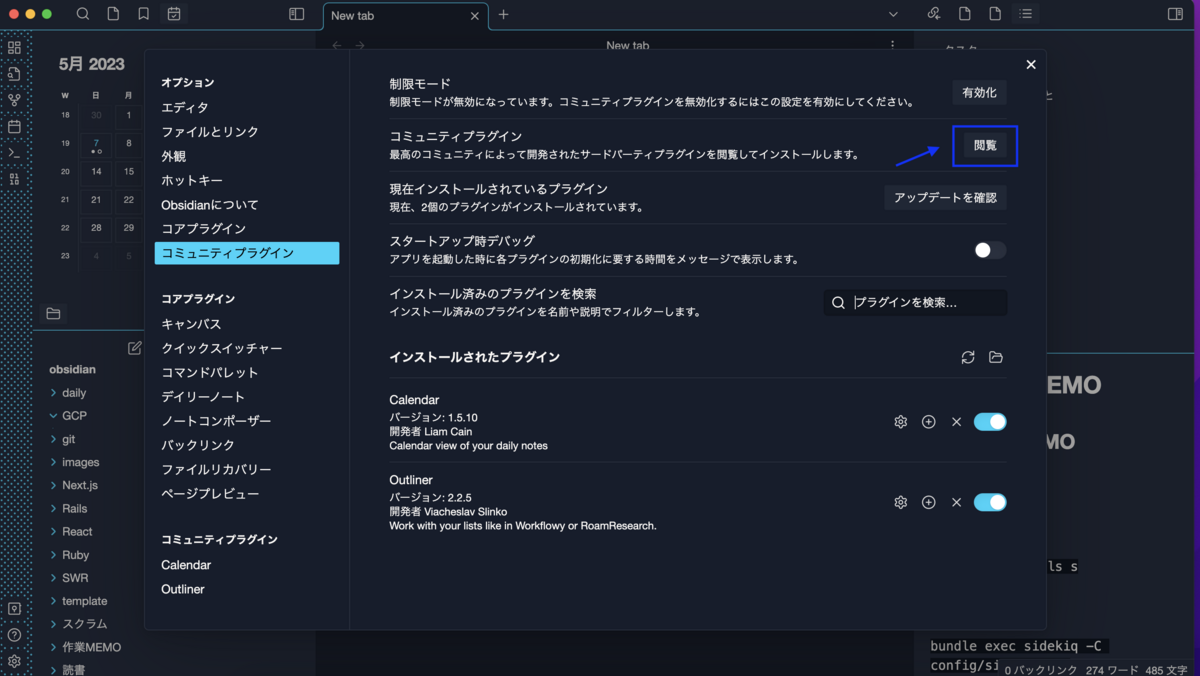
Calendar を検索し、クリックして Install ボタンをクリックし、有効化します。
カレンダーは右サイドバーに追加されているので、左上に移動させます。
2. アウトラインを表示させる
アウトラインは右上のアウトラインボタンをクリックすると表示できます。
3. よく見るノートを右下に配置させる
よく見るノートを選択し、右下にドラッグアンドドロップさせます。
これで設定は完了です。
Daily notes を書いてみる
私は Daily notes のテンプレートは以下です。 このテンプレートはチームメンバーの週報がとても素敵だったので参考にしています。
### タスク #### ✅ todo - [ ] XXX(h) #### 🙅♀️ 今日やらないこと #### 📋 作業メモ #### 🐥 Tweet
毎朝タスクの todo を書いて、やること、やらないことを整理します。
やらないタスクの期限が明確に決まってる場合は、期限日の Daily note のタスクに追加しておきます。
仕事中のメモや新しく学んだこと、考えたことなどは作業メモに箇条書きで書いていきます。
最後に仕事終わり、もしくは振り返りの時間(毎日18時45分)にタスクの抜け漏れの確認、作業MEMOを振り返りながらTweet部分に今日一日の感想をざっくり書きます。
Daily notes のテンプレートは 設定 > デイリーノート > テンプレートファイルの場所 から設定することができます。
さいごに
私の Obsidian の使い方はこんな感じです。
シンプルで使いやすく、動作も軽いのでお気に入りです。
2022年振り返り
2022年を振り返ります。
仕事
今年は7月から新しいプロダクトの開発をやっていました。 今年は新規プロダクトの開発に尽きるという感じです。
今年の前半は組織図機能の開発をしていて、3月にフロントエンドエンジニア2人体制になりました。 フロント1人開発が多かったので、一緒にフロントエンドの相談をしながら開発したり、レビューをしてもらえるのがとても嬉しかった記憶です。 特に週に一回フロントエンド改善デイをやっていて、いっしょに React Router のバージョンを上げるペアプロをしたり React18 の新機能を眺めたりするのが楽しかったなあという感じでした。
今年の後半は新規プロダクト開発のチームに異動になりました。 マネージャーに新規プロダクトの開発どう?と言われたのですが、能力的に自信がないし、ゼロイチ開発を上手くできるか悩んでいました。 ですが、メンバーに憧れてるフロントエンドの先輩がいて、一緒に開発できるのって学べることが多くて成長できるかも。と思い異動を決めました。
会社の多くのプロダクトは、フロントエンドは React で開発していて、Ruby on Rails で空の HTML を表示し、ビルドしたファイルを読み込むという構成なのですが、新規プロダクトは Next.js を採用することにしました。
認証周りを今までは Rails 側でやっていたので、フロントエンドとしてはあまり認証周りを気にせず開発していたのですが、Next.js では Next.js のサーバーを立てる必要があるので認証周りをフロントエンドで対応する必要がありました。 認証の実装をしたことがなく、流れも理解していなかったこともあり認証周りを理解するのはとても苦戦しました… ですが、今までやってないことに挑戦できたこと、理解ができたことは成長を感じることができました。
React 状態管理については、SWR を採用しました。 前のプロダクトでは Redux を使用していのですが、理解するまでが大変だなあと思っていたのと、バックエンドからのデータをそのまま表示することが多く、Redux をあまり上手く使いこなせてないなあと思っていたので、 SWR を使用してみました。
SWR はデータフェッチライブラリで、サーバーからのデータをキャシュしてくれます。 使ってみた感想はとてもシンプルに書けるし、管理するステートが減ってとても良いです。ドキュメントも理解しやすかったのも良かったです。グローバルステートの管理も SWR でできるので、SWR 一つですべて完結できて個人的には感動でした。
こんな感じで今年の後半は技術的にいろいろ挑戦できたことがとても良かったし、嬉しいです。 あと、レビューも丁寧に見てもらたり、相談しながら実装ができたり、先輩の設計やコードを隣で学べたのは個人的にめちゃくちゃ良かったです。 スクラムで実装していると早く実装して、リリースして、後でリファクタしよ。みたいに私はなってしまっていて、結局リファクタしないことがあり、あまりこだわってコードを書けていなかったなあと反省しています。 早く・上手くコードが書けたら…と悩んでいたのですが、先輩の仕事を見ていて学んだことは、最初から早く上手にできる人なんかいないので、時間がかかってもいいから丁寧に、どうしてこのコードを書いたのか言えるようにすることの積み重ねだなあと思いました。(時間をかけすぎるのは良くないので都度相談することも大事)
本
今年は小説をたくさん読みました。
特に流浪の月は良くて、何も分かってくれない、と落ち込んでしまうことがあるけれど、誰か1人だけでも分かってくれる人がいるだけで生きていけるという気持ちになりました。 騎士団長殺しも良くて、なかなかの長編小説なので避けていたのですが、とてもおもしろくて一気に読みました。 隠喩と暗喩に酔う感じが好きなのでとても良かったです。 上手くいえないけど父親として上手く生きられず、後悔してる男たちの物語だと感じました。
")

】")


")

")
")
")
 全4冊セット")
音楽
今年はあまり新しい音楽を聴いていないです。 好きな音楽をずっと聴いていた年でした。
今年は、ART-SCHOOL、ELLEGARDEN の新譜が出ていて、新譜と一緒に ART-SCHOOL、 ELLEGARDEN の古いアルバムをずっと聴いたりすることが多かったです。 音楽を聴いていると聴いていたころにタイムスリップができるの良いですよね。今年は中学生の頃にたくさんタイムスリップしました。
来年はもっといろんな音楽を聴きたい。
生活
今年はランニングをはじめました。落ち込みやすい性格なので気持ちを上手に切り替えられるようになりたいと思ったのがきっかけです。 朝のランニングは走りながらタスクを頭の中で整理したり、夜のランニングは落ち込んだり嫌なことをすっきりさせてくれたり良いことだらけです。 ただ寒いのが苦手なので冬はなかなか走れず… 暖かくなったらたくさん走りたいです。
今年買って良かったものは、 AURALEE のブラウンのモヘアニットと白いワンピース、Davines のオーセンティックオイルです。 AURALEE のブラウンのモヘアニットはゆるっとしてる形がかわいくて、どんな服にも合うのでお気に入りです。AURALEE の白いワンピースも絶妙なかわいい白色なのと丈感が長くてワンピースなのに大人っぽく着れるところが気に入っています。 Davines のオーセンティックオイルは本当にお気に入りで、程よい艶がでるし、まとまってくれるし、こなれた感じが出せる気がしていてお気に入りです。香りもスモーキーな香りで大好きな香りです。
TO 2023
来年は開発していたプロダクトのリリースがあります。 たくさんのお客さんに使ってもらって喜んでもらえたら本当に嬉しいです。
今年はいろいろな挑戦ができたし、学べたこともたくさんありました。 去年の自分よりも自信もついた気がしています。
今年学んだことを大切に、さらにエンジニアとして成長していける年にしていきたいです。
あと、キャリアやどんな自分になりたいのかぼんやりしている気がしてるので、今年は明確にしたり目標ができたらいいなあ。
2021年振り返り
2021年を振り返ります。
仕事
今年から新しいチームに異動になりました。
2021年1月にリリース予定のプロダクトを引き継ぐ形でフロントエンドの開発を主にやっていました。 Redux を使ってるプロダクトなのですが、はじめてだったので、1月、2月は慣れるのに苦労しました。
10月までエンジニアはバックエンドの先輩とフロントエンドの私で二人だったので、他のチームに比べると規模は小さいけれどフロントエンド以外の領域も積極的に挑戦できました。 今年の前半は基本ペアプロしたり、バックエンドを教えてもらったりしてた気がします。 最初は二人で寂しかったけれど、いつも盛り上げてくれたり、チームメンバーの元気がないときはすぐに気づいてくれたり、一年間大きな問題なく開発できたのはバックエンドの先輩のおかげだなあと、とても感謝してます。
ファシリテーションがすごく苦手なのですが、チーフのアドバイスのおかげでチームのみんなに褒めてもらえる機会が増えました。 MTGの目的を意識したり(意見を発散するMTGなのかとか)、まとめようとしない、議論の焦点を合わすこと・発展させるが大事っていうことを意識するようにしました。
2020年は体調を崩しがちだったので、健康にチームの雰囲気良く開発することが目標だったのですが、チームメンバーに恵まれて充実した開発ができました。 上手く意見がまとまらなかったり、緊張しちゃうのがコンプレックスなのですが、みんなで議論しながら様々な機能を開発できた気がしています。 人数が少ないながらもいろんな機能や改善をリリースできた気がします。
今年の後半からは、ヘルプでフロントエンドの先輩が Review や実装の相談に乗ってくれるようになりました。 丁寧にコードを見てくれたり、設計の話も教えてくれたりして、すごく良かったです。 先輩にapprove もらったときは成長が実感できて久しぶりにコードを書いて嬉しい気持ちになりました。
2022年は今開発しているプロダクトの成長の年です。(2021年にいろいろ準備してた) たくさんやることがあるので、2022年が終わるころにはプロダクトの成長と一緒にフロントエンドエンジニアとしてもっと成長していたいです。
本
今年は、エッセイをたくさん読みました。
気分的に穏やかな気持ちでいたかったのと、安定して成果を出せてる人の日常が知りたかったから意識的にエッセイばかり読んた気がします。 生活の一部を覗いてる感覚と、文字からその生活の擬似体験ができるのが良いです。
小説はあまり読んでいないけれど、クララとお日さまはとても良かったです。 心を持ったロボットほど切ないものはないと思いました。
")
")

")
")
")



")




 (ディスカヴァー携書)")


音楽
今年もSpotifyの月曜日と金曜日のDiscover WeeklyとRelease Radarが楽しみで毎週頑張りました。
冥丁の新譜はとても良かったです。去年リリースされたアルバムも良かったのですが、引き続き和や懐かしさを感じられる雰囲気が良かったです。
Lillies and Remains の6年半ぶりの新譜もすごく良かったです。ニューウェーブ的で、ちょっと儚い感じがとても良かったです。
Noah の新譜も良くて、冷たくて切ない音が心地よかったです。
生活
今年は季節ごとに花や枝ものを部屋に飾りました。 季節感を感じられて、気持ちが穏やかになったので続けていきたいです。 花屋さんで季節の花を眺めて、花の名前を覚えるのも好きな時間になりました。
服を季節ごとに整理するようにしました。 定期的にクローゼットを整理することで、すっきりした気持ちで新しい季節を迎えられるので良かったです。続けていきたい。
あと、高い服を買って大切に着るようにしました。 今までは、UNIQLOなどで買って次の年にはもう着ないみたいなことが多くて、安いからいいやって捨ててしまう服が多かったので、高くても良いから気になった服は大切に着るようにしてみました。 服のお手入れが好きになったり、逆に服欲が減ってクローゼットがすっきりしました。
A.P.Cで買ったドット柄のワンピースがお気に入りなので、2022年の春と秋もたくさん着たい。
TO 2022
仕事振り返りでも書いたのですが、今年は今開発してるプロダクトの成長の年です。 成功すれば、会社の売上にも貢献できるし、自分の自信に繋がりそうな気がしています。
小さい規模で開発していたので、他チームと比べてしまい、今年は急いで開発してリリースして価値を提供しなきゃ!みたいなのが自分の中にありました。 たくさんリリースできたのは良いのですが、設計やコード部分を疎かにしてしまったのと本当にユーザーの欲しいものを提供できてたのかなと反省しています。
2022年は自分が決めた設計やコードに対してなぜそうしたのかをきちんと説明できるように意識しながら開発したいと思っています。
あと髪の毛を明るくしてみたいなあって思ってます。金髪にしようかな。
2020年振り返り
2020年を振り返ります。
2020年を月ごとに
1月
チーム異動になった。
フロントエンドは一人で、私で大丈夫なのかなってすごく不安だったけど、チームのみんなは優しくて頑張ろうと思った。
2月
少しずつチームのみんなに慣れてきたし、先輩のPRが丁寧で分かりやすかったり、リリースの共有等のSPチームとの連携もすごく丁寧で真似しようと思った。
チームのみんなは面白くて優しくて素敵な人だった。
何故か遊戯王にはまった。
3月
フロントエンド専任のエンジニアがいないプロダクトだったので、フロントエンドの底上げをしたいなあと思って、将来的にどうしたいのか、どのように改善したいかを考えたりした。
一人では上手くできなくて、技術顧問の方に相談した。
改善ポイントを一緒に考えてくれたり、一緒にコードを読む会をやってくれたり、PRも出してくれたりして頑張ろうと思った。
4月
引き継ぎフロントエンドの底上げや既存コンポーネントを共通コンポーネントライブラリのSmartHR UIに置き換えたりとかした。
プロダクトのpdf表示部分のリファクタもできた。
何故か幽遊白書を一気に全話見た。
5月
チーム内でReact Hooks勉強会をした。
チームのみんなの役に立ててたらいいなあと思った。
エンジニア向けの採用サイトを作ってリリースした。
コツコツ有志で作ってたけど、やっと5月にリリースできた
6月
チームにフロントエンドエンジニアが一人増えた。嬉しい。
一緒にフロントエンドガイドラインを作ったりした。
7月
ずっと雨が降ってた気がする。
天気で体調が悪くなったりとかは今までなかったんだけど、体調がけっこう悪くなりがちだった。
少し広い家に引っ越しをした。駅からも会社からも遠くなった。
8月
体調が悪くなった。
なんかもうしんどくて何がしんどいのか分からなかった。
snsを見るとなぜか人の意見とか批判が全部自分に向けられてるような気がした。
転職して頑張れたのに、なんだか体調が悪いし一気に怖くなった。
9月
snsをやってた時間を本を読む時間にした。
いい本に出会えたとき、いい言葉を見つけたときは気分がいい。
東京都庭園美術館に行ってみた。建築は何も分からないんだけど、自分がここに住んでることを想像してみると楽しかった。
無理せずもう一回頑張ろうと思った。
10月
SmartHR UIの担当になった。
もともとSmartHR UI担当の先輩は一緒に仕事をしたことがなかったんだけど、PRを見てると実装がうおー!なるほど!!ってことが多くてすごく勉強になった。
犬を飼い始めた。
ペットショップでポメラニアンの子犬を見かけて何故か衝動的に飼い始めた。
家族が欲しくなったのかも知れない。
名前はむくにした。
むくはよく首をかしげるし、私の後ろをずっとついてくる。
11月
はじめてnpmのパッケージを作った。
新しいことができるようになることはこんなに嬉しいことなんだなあって改めて思った。
SmartHR UIのアクセシビリティ対応をするためにアクセシビリティのことを勉強した。
新しいことを勉強してできるようになるのは楽しい。
SmartHR UI専任で担当してると、自分の担当プロダクトがあって大変なのにめちゃくちゃコミットしてくれる先輩の大変さが分かった。
もしプロダクトに戻ったとしても積極的にSmartHR UIにコミットするのは続けたいって思った。
12月
昨年やってたプロダクトのお手伝いをすることになった。
成長してる感覚が全くなかったんだけど、去年やってプロダクトに戻るとフロントエンドこうした方がいいなあっていう改善がでてきてなんだか成長を少し実感できた。
プロダクトと並行してSmartHR UIの開発も少しできた。
STUDY
お仕事でHMRの module.hot.accept 部分の読み込み部分をDynamic Importで書いていてエラーになってしまい、HMRが使えなくなってしまったことがありました。
CommonJSに変えることでHMRを有効にすることができたのですが、なぜなんだろう?というのを技術顧問の方に質問するとHMRの仕組み部分を教えてくれてもっと知りたくなってHMRでファイルを変更してからブラウザで変更が反映されるまでを調べたりしました。
普段使ってるライブラリの中身の仕組みを見てみるのは楽しいです。
バックエンドエンジニアの人もフロントエンドを書くのでチームのフロントエンドの底上げをしたいなあと思ってReact Hooksの使い方という勉強会をしました。
勉強会をやるって決めると勉強会の準備のためにReact Hooksすごく勉強したのですごく良かったです。
SmartHR UIのアクセシビリティ対応をやるのにアクセシビリティを一から勉強しました。
なぜやるのかを考えながら勉強してると、改めてWebの思想的なのを考えさせられたような気がしました。
C++ 言語は読めないんだけど、Chromiumのコードは読んでみたいなあというぼんやりとした好奇心がずっとあって、今年は実行に移して少し眺めることができました。
C++ 言語勉強してみようかな…できるかな…
去年は自分の得意分野的なのを見つけられたらなあと思ってたんだけど、見つけられずでした。
上手くできなくて、自分が何が得意なのか好きなのかすごく悩んだ気がします。
来年は焦らず、目の前のお仕事に真摯に向かい合いつつ、成長を実感できたらいいなあって思います。
興味を持ったことについては深堀りして調べたりできたら100点にしよ。
BOOK
技術書

Form Design Patterns ―シンプルでインクルーシブなフォーム制作実践ガイド
- 作者:Adam Silver
- 発売日: 2019/12/24
- メディア: 単行本(ソフトカバー)

レガシーコードからの脱却 ―ソフトウェアの寿命を延ばし価値を高める9つのプラクティス
- 作者:David Scott Bernstein
- 発売日: 2019/09/19
- メディア: 単行本(ソフトカバー)


コーディングWebアクセシビリティ: WAI-ARIAで実現するマルチデバイス環境のWebアプリケーション
- 作者:Heydon Pickering
- 発売日: 2017/03/30
- メディア: Kindle版
小説・エッセイ
")
")
")
- 作者:又吉 直樹
- 発売日: 2020/04/10
- メディア: 文庫
")
- 作者:本多 孝好
- 発売日: 2005/09/16
- メディア: 文庫
")
")
- 作者:村上 春樹
- 発売日: 2010/06/10
- メディア: ペーパーバック
")
")
- 作者:春樹, 村上
- 発売日: 2016/09/28
- メディア: 文庫
")
日日是好日―「お茶」が教えてくれた15のしあわせ (新潮文庫)
- 作者:典子, 森下
- 発売日: 2008/10/28
- メディア: 文庫



")
- 作者:川上 弘美
- 発売日: 2004/09/03
- メディア: 文庫
今年は小説とエッセイをたくさん読みました。
Twitterを見る時間が減ってお昼ごはんを食べた後の20分、寝る前の20分や隙間時間に読む時間が増えました。
今年一番良かった本は 愛するということ で、「愛は技術だろうか。もし技術だとしたら、知力と努力が必要だ。」の文章が気になって読んでみました。
愛されることばかりに目を向けて外見を気にしたり、誰かに愛されるためにどうしたらいいのか考えたりするけど、私は愛することについて努力したことがないです。
本の中で愛の性質は「配慮、責任、尊重、知」と書いてあって、尊敬する人や先輩、憧れのエンジニア、今働いている会社の人はこの4つが自然とできているなあと思いました。
MUSIC
Spotifyの月曜日と金曜日のDiscover WeeklyとRelease Radarが楽しみで毎週頑張っています。
振り返ると今年はあんまり明るい曲は聴いていないみたいです。
TO 2021
2020年は生活ががらっと変化してついていけなくて辛かったです。
変化の適応能力が無さ過ぎるので、こんなんじゃ私自然界に出るとすぐ絶滅するんだろうなあと思ったりしました。
引っ越しをして、犬との生活が始まってからは毎日朝は掃除機をかけて拭き掃除をして、洗濯をして、花の水を変えたりしてから仕事、というのを日課にしてるのですが、
気持ちよく仕事ができるし、家のことを後回しにして、仕事に集中しすぎる自分よりは、毎日ちゃんと家事をしてご飯を作って仕事も頑張る自分の方が好きだなあと気づけました。
来年は毎日の日課は継続しながら、目の前のことを一生懸命取り組んだり、新しいことに挑戦できたら嬉しいです。
Chromiumのソースコードを読んでみる
この記事はSmartHR Advent Calendar 2020 10日目の記事です。
はじめに
私は、普段フロントエンドエンジニアとしてWebフロントエンドのコードを書いたりしています。 新しいHTML/CSS/JavaScriptの仕様だったり、新しいAPIのドキュメントを読んだりしていると、
この新しい仕様ってブラウザにどんな風に実装されてるんだろ?
↓
Chromiumのコードって公開されてるから見られるんじゃないかな
↓
いや、そもそもChromiumのソースコードって私でも見ても分かるのかな…
↓
公開されてるし、ちょっと覗いてみるだけでも何かいいことあるかも
と思いたってChromiumのソースコードを読んでみることにしました。
この記事はChromiumのコードを読んだことがない私がChromiumのコードを読むために行った手順と気付きを書いています。
ゴールを決める
Chromiumのソースコードを読んでみると決めたものの、Chromiumのソースコードは巨大で規模がとても大きいです。 しかも私はC++ 言語を触ったことない、全く読んだことがない、書いたことがないです...
なので、とりあえず div タグ等のHTMLタグを生成してる辺りのコードを見つけて実装を眺めてみるっていうことをゴールにします。
Chromiumとは
Chromium オープンソースのウェブブラウザ。 主に C++ 言語で書かれています。
Chromiumを利用しているプロダクト
- Google Chrome
- Microsoft Edge
- Opera
- Brave
実際に読んで見る
ソースコードを読む準備
Chromiumのソースコードこちらを参考にgitで落としてくることが可能なようですが、Chromiumのような巨大なプロジェクトのコードを落としてくるのは、
- かなり時間がかかりそう
- C++ 言語用にエディタを整えるのが大変そう
- さくっと読んでみたい
という理由から、Chromium Code Searchを使って読んでみようと思います。
Chromium Code Search とは
Chromiumのソースコードの中から自由に検索ができ、クラスの定義や関数の呼び出し元、変数の参照元などをブラウザ上で辿ることができます。
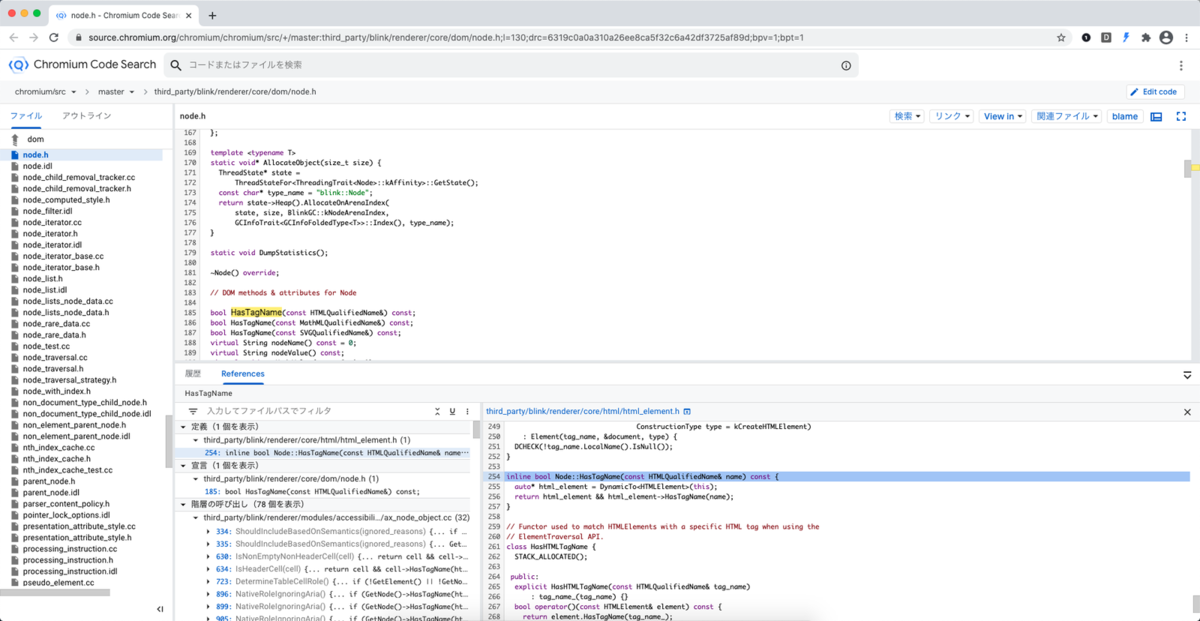
ディレクトリ構成
コードを読む準備ができたので、さあ、読むぞ!という意気込みですが、膨大なソースコードを手当たり次第見ていっても全体像が分からないので、ざっくり全体を把握するためにディレクトリ構成を見ていきます。
src
- android_webview
- apps // Chrome packaged apps
- base
- breakpad
- build
- cc
- chrome // GoogleChromeのオープンソースのアプリケーション層
- components
- content // multi-process sandboxed browserに必要なコアコード
- device
- net
- sandbox
- skia + third_party/skia
- sql
- testing
- third_party // 画像デコーダー、圧縮ライブラリ、WebエンジンBlinkなどの外部ライブラリ
- blink // レンダリングエンジン, HTML,CSS, scriptをペイントコマンドや状態変化に変換するWebエンジン
- ...
- tools
- ui/gfx // 共有グラフィックスクラス。これらは、ChromiumのUIグラフィックのベースを形成
- ui/views // UI開発を行うためのシンプルなフレームワーク。レンダリング、レイアウト、イベント処理を提供
- url // GoogleのオープンソースURL解析および正規化ライブラリ
- v8 // V8Javascriptライブラリ
もっと詳しく知りたい方は以下に詳しく記載されているので読んでみてください。
HTMLタグが生成されているっぽいところを探す
ディレクトリ構成をざっと見たので、HTMLタグが生成されているところを探していこうと思います。
私が知っている情報は
なので、とりあえずblinkフォルダを覗いてみようと思います。
blinkフォルダ以下はこんな感じです。

このディレクトリのREADMEには
renderer/: code that runs in the renderer process (most of Blink).
と書いているので、renderer配下にいってみます。
renderer配下を見てみると renderer/core/html/ といういかにもっぽいディレクトリを見つけました。
中身を見てみると、
html_div_element.cc , html_anchor_element.cc, html_li_element.cc などのHTMLタグの名前のファイルがたくさんあります。
html_div_element.ccに div タグの実装がありそうです。

div の実装みたいなところ見つけた
では、html_div_element.cc の中身を見ていこうと思います。
// html_div_element.cc ... #include "third_party/blink/renderer/core/html_names.h" namespace blink { HTMLDivElement::HTMLDivElement(Document& document) : HTMLElement(html_names::kDivTag, document) {} void HTMLDivElement::CollectStyleForPresentationAttribute( const QualifiedName& name, const AtomicString& value, MutableCSSPropertyValueSet* style) { if (name == html_names::kAlignAttr) { if (EqualIgnoringASCIICase(value, "middle") || EqualIgnoringASCIICase(value, "center")) { AddPropertyToPresentationAttributeStyle(style, CSSPropertyID::kTextAlign, CSSValueID::kWebkitCenter); } else if (EqualIgnoringASCIICase(value, "left")) { AddPropertyToPresentationAttributeStyle(style, CSSPropertyID::kTextAlign, CSSValueID::kWebkitLeft); } else if (EqualIgnoringASCIICase(value, "right")) { AddPropertyToPresentationAttributeStyle(style, CSSPropertyID::kTextAlign, CSSValueID::kWebkitRight); } else { AddPropertyToPresentationAttributeStyle(style, CSSPropertyID::kTextAlign, value); } } else { HTMLElement::CollectStyleForPresentationAttribute(name, value, style); } } } // namespace blink
kAlignAttrという型の名前や middle, centerや left , right の 値で条件分岐をしていることから div タグのalign属性の実装していることが分かります。
HTML5ではalign属性は廃止されていますが、HTML5以前の互換性を保つためにまだ実装の記述がされている?のかな(分からないです。予想です。)
html_div_element.h というファイルがincludeされているので、次はこちらを見ていきます。
// html_div_element.h ... namespace blink { class CORE_EXPORT HTMLDivElement : public HTMLElement { DEFINE_WRAPPERTYPEINFO(); public: explicit HTMLDivElement(Document&); private: void CollectStyleForPresentationAttribute( const QualifiedName&, const AtomicString&, MutableCSSPropertyValueSet*) override; }; } // namespace blink #endif // THIRD_PARTY_BLINK_RENDERER_CORE_HTML_HTML_DIV_ELEMENT_H_
class CORE_EXPORT HTMLDivElement : public HTMLElementから
HTMLDivElement が定義されていますが、HTMLElement を継承していることが分かります。
では次に HTMLElement を定義している html_element.h を見てみます。
// html_element.h ... namespace blink { struct AttributeTriggers; class Color; class DocumentFragment; class ElementInternals; class ExceptionState; class FormAssociated; class HTMLFormElement; class KeyboardEvent; class StringOrTrustedScript; class StringTreatNullAsEmptyStringOrTrustedScript; enum TranslateAttributeMode { kTranslateAttributeYes, kTranslateAttributeNo, kTranslateAttributeInherit }; class CORE_EXPORT HTMLElement : public Element { DEFINE_WRAPPERTYPEINFO(); ...
Color クラス、 KeyboardEvent クラスがあったり、読んでいくとdraggable() , innerText() , offsetHeightForBinding()という名前のメソッドがあることからタグ固有のふるまいではなく共通のHTML要素のふるまいを書いているファイルのような予感です。
また、html_element.h というファイル名、draggable() , innerText()というメソッドがあることからこのファイルは HTMLElement の実装をしていそうです。
HTMLElement は Element を継承しているので次は element.h を見てみます。
// element.h namespace blink { class AccessibleNode; class Attr; class Attribute; class CSSPropertyValueSet; class CSSStyleDeclaration; class CustomElementDefinition; class DOMRect; class DOMRectList; class DOMStringMap; class DOMTokenList; ... class CORE_EXPORT Element : public ContainerNode, public Animatable { DEFINE_WRAPPERTYPEINFO(); ...
element.h というファイル名、AccessibleNode, Attribute, などのクラス、ずっと見ていくと ClassNames(), scrollWidth() , innerHTML()というメソッドがあることからこのファイルは Element の実装をしていそうです。
ContainerNode, Animatableを継承しているのですが、このまま継承しているクラスをざっと見ていくと、
Element → ContainerNode → Node → EventTarget という流れで継承していました。
ここで HTMLElement - Web API | MDN を見てみると
要素はこれを継承したインターフェイスを通して実装されています。

HTMLElement - Web API | MDN より
と書かれていて、Chromiumの実装と同じことが分かります。
合わせてMDNのHTMLElement, Element のページを見てみると、記載されているプロパティ名と同じ実装を見つけることできます。
また、 divタグは HTMLDivElement → HTMLElement → Element → ContainerNode, Animatable → Node …
のような実装の流れだったのですが、 a タグなど他のHTMLタグの実装をみても同じ流れでした。
このことからHTMLタグはHTMLElementクラスから派生してできていることが分かりました。
divの実装を探してみてのまとめ
third_party/blink/renderer/core/html/配下に、HTMLタグごとのファイルがある- HTMLタグは
HTMLElementクラスを継承してできている HTMLElementやElementオブジェクトの実装が気になったらhtml_element.h,element.hを読んでみると分かりそうHTMLElement.XXXやElement.XXXとか使ったりするけど、ちょっと理解が深まった気がする
↑が実際にChromiumのソースコードを読んでみての気付きです。
見ていて気になったところ(おまけ)
accessibility
third_party/blink/renderer/core に accessibilityフォルダがありました。
最近働いている会社でaccessibility勉強会をやっていて気になりました。
ここにARIAの実装とかAOMの実装が書いてあるのかな
potal
PortalsというWICGによって提案されているページ間の遷移をシームレスにすることができる仕組みがあるのですが、third_party/blink/renderer/core/html にpotalディレクトリがあったので、ここでpotalタグが実装されてる気がしました。
まとめ
今回は div タグのHTMLタグを生成してる辺りのコードを見つけて実装を眺めてみました。
C++言語がよく分かっていないので、関数名、クラス名で予測しながらでしか見ることができなかったのですが、ディレクトリ構成を眺めて全体像がなんとなく分かったり、いつも何気なく使ってるdiv タグの実装から HTMLタグはHTMLElementクラスから派生してできているというのが分かったり、HTMLElementやElement オブジェクトの実装を覗いてみたりすることができました。
使用してるライブラリの新しいバージョンのRelease Noteを読むだけではなく、変更されてるコードを読むことでより理解できることがあります。 ブラウザの新しいAPIができたとき仕様のドキュメントを読むだけではなく、実装を見てより理解を深め、ちゃんと理解してWebフロントエンドのコードが書けるになったらなあと思いました。 (C++言語何も分からなかったので何年先になるんだろう…)
Chromiumのコードって一生読めないものって勝手に思っていましたが、いざ眺めてみるとクラス名、メソッド名で予測しながらほんの少しだけ読めて少し嬉しくなりました。
参考
Chromium のソースコードの歩き方
Getting Around the Chromium Source Code Directory Structure - The Chromium Projects
HTMLElement - Web API | MDN
React Hooksの使い方
このあいだチームのバックエンドエンジニア向けにReact Hooks勉強会を開催しました。
チームのみんなでプロダクトのフロントエンドの底上げをしたくて、React Hooks啓蒙活動です!
改めてReact Hooksについて勉強&まとめることができたのでReact Hooks勉強会の内容をブログにも書いておこうと思います。
これは何?
- Hooksとは何か?
- Hooksを使うと何が変わるのか?
- Hooksの使い方
- Hooksを書くときのルール
👆についてまとめてます。
対象は
- Reactは書けるけどHooksって何?
- Hooksって聞いたことあるけど何がすごいの?
- Hooks使いたいけど、よく分からないんだよね…
な人向けです。
背景
これから積極的にReact Hooksを使っていきたいなあと思っています。
でもいきなりHooks使おう!ってなっても、 Hooksって何? 使うといいことある? どういいの? 難しいの? って疑問があると思います! なのでチームのみんながHooks良さそう!使ってみようかな!って思えるようなHooksについての入門資料です。
ゴール
Hooks良さそう!使ってみようかな!って気持ちになってチームのみんながHooksで書いたPR作成できる!
Hooksって何?
クラスコンポーネント使わなくても関数コンポーネントでstateなどの機能が使えるようになるやつです!
- useState
- useEffect
👆を使うと関数コンポーネントでstateが使えたり、ライフサイクルメソッドっぽいことができます。
関数コンポーネントで書きたい理由
👦: Q. クラスコンポーネントで書けるのにどうして関数コンポーネントを使うの?
👨: A. 👇
- クラスComponentと比べてスッキリ、綺麗に書ける
- 可読性が良くなる
- クラス内の this の挙動が難解
- 記述が冗長になりがちで、時系列が複雑なライフサイクルメソッドの挙動
これまでのReact
アプリケーションのロジックに関わるコンポーネントはクラスコンポーネント
ロジックをコンポーネント間で再利用するのが難しい
render props や higher-order componentsがあるけど、コンポーネントの再構成が必要だし、ラッパー地獄になりやすいし、可読性が低くてコードを追うのが大変です…
これからのReact
関数コンポーネントで書けるようになる
アプリケーションのロジックに関わるコンポーネントが関数コンポーネントで書けるようになります!
ロジックを再利用できるようになる
Custom Hookという独自にhookを作成することを使うとロジックを再利用できるようになります。
再利用できるようになり、コードも綺麗に書けるようになります! ReactのロジックをOSSとして気軽に共有できます!
👦: Q. じゃあ全部Hooksで書いた方がいいの?
👨: A. 新しいコンポーネントはHooksで書いていくのがおすすめ
ref. https://ja.reactjs.org/docs/hooks-faq.html#should-i-use-hooks-classes-or-a-mix-of-both
クラスコンポーネントはいつかなくなるかもしれません… 何年後かのクラスコンポーネント置き換えtaskが辛くならないために新しく作成するコンポーネントは関数コンポーネントで書きたいです!
Hooks使うのは強制ではないです。無理だ!って思ったらクラスコンポーネントでも大丈夫です! でもクラスコンポーネントは将来deprecatedになると思うのでこの機会にぜひ!
Hooks
(チーム内の)プロダクトでよく使いそうなHooksたち
1. useState
関数コンポーネントで状態を持つことができるようになります!=> stateが使える
useStateの基本
const [state, setState] = useState(initialState);
👉 配列の1つ目にstate名(配列が返ってくる)、2つ目に関数(setState)、useStateの中に初期値が入ります。
こんな感じ
const [count, setCount] = useState(0)
useStateの実装
例えば、以下のようなカウンターの実装
クラスコンポーネント
関数コンポーネント hooks
💪+α useStateの中身
const state = useState(0);
console.log(state);

console.logに出してみると以下のようなことが分かります。
- useStateは配列を返す
- 初期値が配列の0番目に入ってる
- 配列の1番目にsetStateの関数っぽいのがある
2. useEffect
関数componentで副作用処理を扱う(DOMの変更、API通信)ことができます。 ライフサイクルメソッドっぽいことができます。
useEffectの基本
useEffect(didUpdate);
👉 didUpdate部分に副作用処理を扱う(DOMの変更、API通信)を書きます。
👦: Q. どのタイミングで実行されるの?
👨: A. 最初の描画時または、再レンダリング時です。
マウント時、再レンダリング時(コンポーネントの全てのstateが変更されるとき)に実行されます。
👦: Q. この値が変更したときだけ実行したい…
👨: A. useEffect の第 2 引数として、この副作用が依存している値の配列を渡します!
useEffect(() => { document.title = `クリック数: ${count}回` console.log('render') }, [count]) // countの値が変更されたときだけ実行されます
👦: Q. マウント時だけ実行したい…
👨: A. useEffect の第 2 引数として、空の配列を渡します!
useEffect(() => { mount時の処理 }, []) // 第2引数に空の配列
useEffectの実装

👆 mount時とcountの値が変更されるとuseEffect内の処理が実行されている
4. useCallback
パフォーマンス向上のためのフックです。 callback関数(イベントハンドラー) をメモ化します。
メモ化
- プログラムの高速化のための最適化技法の一種
- 関数の結果を再利用、一時的に保持する
useCallbackの基本
const memoizedCallback = useCallback( () => { doSomething(a, b); }, [a, b], // 依存している値の配列 );
コールバック関数と、依存している値の配列を渡します。 依存配列の要素(a, b)が変化した場合にのみメモ化した値を再計算します。
👦: Q. useCallbackするとどうなるの?
👨: A. 不要に新しく関数インスタンスを作成することを抑制し、不要な再描画を減らすことができます。
不必要なrenderを避けるためにReact.memo(stateやpropsに変更がなければ再レンダリングを行わない)等の参照の同一性を見るよう最適化されたコンポーネントにコールバックを渡す場合に便利です。
👦: Q. useCallbackしないとどうなるの?
👨: A. 全てのcomponentが再renderしてしまい、関数も再生成されてしまいます
useCallbackの実装
useCallbackしない場合

👆 Buttonクリック時fooButtonをクリックするとbarButtonのの関数もrenderされてしまってる
useCallbackした場合

👆 Buttonクリック時fooButtonをクリックするとfooButtonの関数のみ実行
useCallbackはReact.memoと一緒に使うと真の力を発揮するっぽい!
5. useRef
DOMを操作したり、クロージャー内で宣言された値へアクセスできます。 UIの更新に関連しない状態を管理したい場合に使用するイメージです!
useRefの基本
const refContainer = useRef(initialValue);
書き換え可能な値を .current プロパティ内に保持することができる「箱」のようなもの
useRefの実装
DOM操作
クロージャー内で宣言された値へアクセスしたい場合
💪+α 更新前のStateの値を使いたい場面
6. Custom Hooks
独自のhookを自分で作成できます。 独自のhookを作成し、コンポーネントからロジックを抽出することで、ロジックを再利用することができるようになります。
ReactのロジックをOSSとして気軽に共有できるようになったので、探してみるとたくさんOSSのReact Hooksがあります!
👇のOSSを眺めてみるとイメージしやすいかも!
https://nikgraf.github.io/react-hooks/
コードとDEMOは👇の方が探しやすいかも!
https://github.com/streamich/react-use/
(7. useMemo)
プロダクト内では使うことはなさそうなので省略します! 興味ある人は調べてね!
(8. useContext)
プロダクト内では使うことはなさそうなので省略します! 興味ある人は調べてね!
(9. useReducer)
プロダクト内では使うことはなさそうなので省略します! 興味ある人は調べてね!
Hooksのルール
Hooksを書くときに気をつけて欲しいこと&守って欲しいこと
1. Hooksはループや条件分岐の中で呼ぶことはできません!
// これはダメ const Ng = () => { if (condition) { useEffect(() => {}, []); } } // これはOK const Ok = () => { useEffect(() => { if (condition) { // } }, []); }
2. 関数Componentの中からのみ呼べます!
Custom Hooksとして切り出した関数の中では呼ぶことはできるので注意!
3. Custom Hooksを作るときはuseXXXの命名規則に!
この名前にすることでESLint PluginなどでHooksだと認識してくれるようになります。
ESLint Plugin
HooksのESLint Pluginです。
depsの指定忘れを検知してくれます。 基本的には従っておいた方がいいです。
const App = () => { const foo = "..."; const bar = "..."; const handler = useCallback(() => { someFn(foo, bar); // fooがdepsに指定されていないのでひっかかる }, [bar]); }
意図的にやっている場合やESLint Pluginが誤検知してる場合は、eslint-disableのコメントで無効にできます。
https://eslint.org/docs/user-guide/configuring#disabling-rules-with-inline-comments
まとめ
チームのプロダクトで良く使いそうなReact Hooksについてまとめてみました!
このReact Hooksについての内容はチームのみんなでプロダクトのフロントエンドを良くしたいなあと思って作ったものです。
React Hooks使いたいけどなかなか…って思ってた人や、プロダクトのフロントエンドを良くしたいなあって人の参考になれば嬉しいです。
参考